MXNet YOLO3 로 사람 디텍터 만들어 보기
2020년 02월 22일 작성TL;DR
코드는 여기1
모델 주를 쓸때는 각 딥러닝 프레임워크별로 제공하는 성능표를 참조하자.
시작하며
최근 Person Tracking 프로젝트를 맡게 되었다. 여기에 사용할 프레임워크를 이것저것 알아보다가 앞으로 모든 프로젝트에 MXNet/Gluon 을 쓰는 것으로 결정했다.
문서도 많고 내용도 체계적이며 코어 API 들도 맘에 들었다. 결정적으로 AWS에서 주도적으로 관리하고 있어서 모델이 빠르게 추가되고 성능도 안정적이다.2
본 글에서는 이 Gluon 에 있는 YOLO 예제3를 좀 설명하고, 거의 실시간으로 사람만 찾는 모델을 만들어본다.
개인적으로 머신러닝 프로토타입을 만들 때 다음과 같은 순서로 진행한다.
- 모델 선택
- 모델 테스트 / 최적화
- 데이터 준비
- 하이퍼파라미터 최적화
- 파인튜닝 / 트랜스퍼러닝
- 배포
본 글에서는 1, 2의 내용만 다루어본다.
모델 선택
대부분의 프레임워크들은 사용자들의 편의를 위해 미리 학습된 모델 주(Model Zoo) 를 제공하고 있다.
Gluon 에서는 모델 주와 함께 퍼포먼스 테이블4도 제공하고 있어서 모델을 선택할 때 큰 도움이 된다.
여기서 제공하는 mAP 는 COCO 데이터 셋에서 결과를 평가하는 기준으로 IOU 를 조금씩 올려가면서 얻은 각 AP 의 평균을 말한다. 따라서 VOC 나 기타 다른 데이터셋으로 학습한 모델은 해당 수치로 평가하지 않는다.
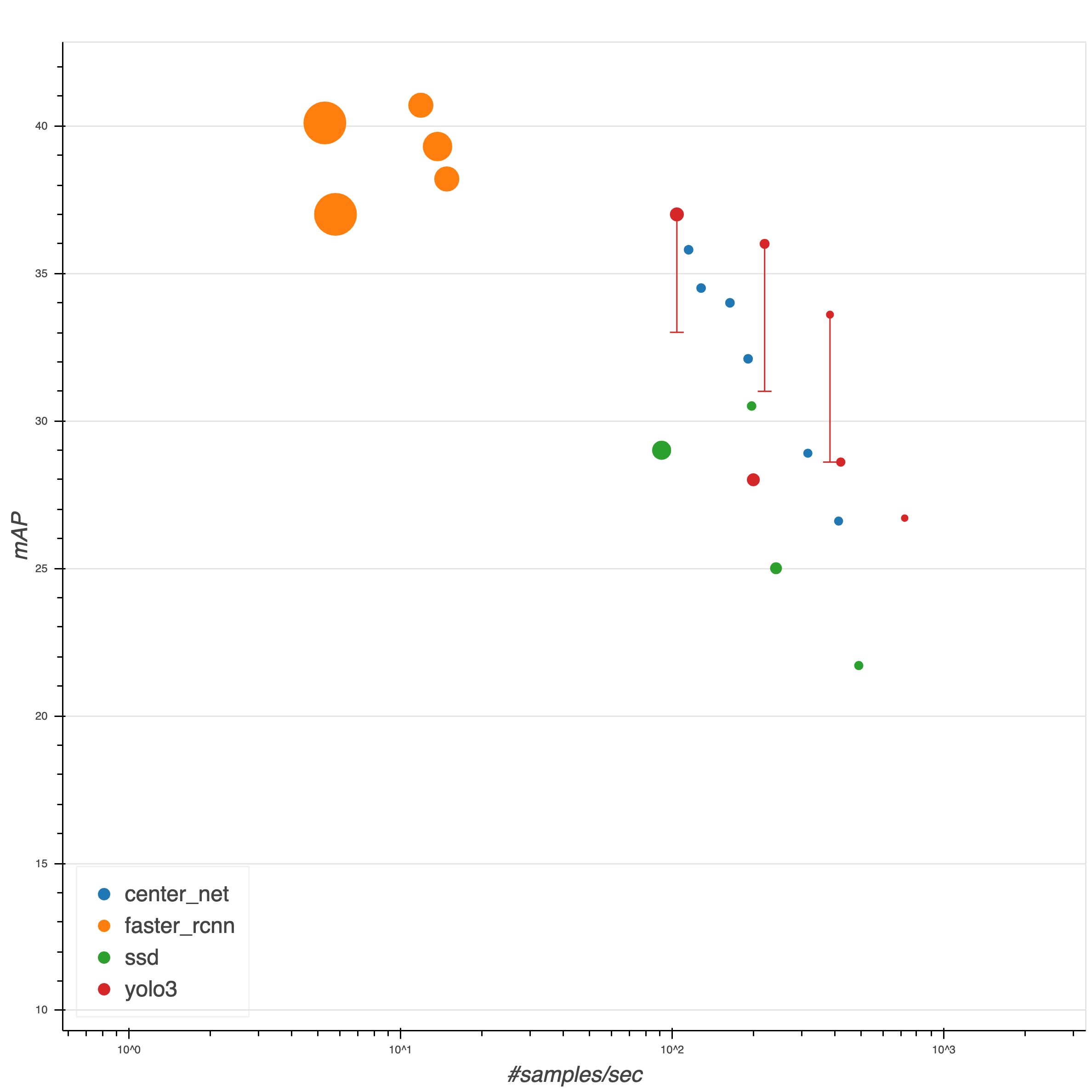
당연히 정확도(mAP) 는 높을수록 좋다. 그리고 속도는 정확도와 반비례 관계에 있다. 둘의 트레이드 오프를 잘 따져서 모델을 선택하면 된다.
본 글에서는 YOLO 를 집중해서 보려고 한다.
논문대로의 구현이면 사실 SSD 나 YOLO 나 성능차이가 없고 오히려 CeterNet 계열이 더 나은 선택일 것이다. 하지만 MXNet 에서는 추가 데이터, 데이터 오그멘테이션 등을 통해 YOLO 에 대해 논문의 성능보다 4~5% 더 개선한 모델을 제공하고 있기 때문이다. (SOTA 모델 성능을 4~5% 개선하는 것이 얼마나 힘든지는 모델 튜닝을 해본 사람이면 잘 알 것이다.)
우리는 사람만 찾을 계획이므로 사람(Person) 카테고리에 대한 성능만 따로 보자.

가장 뛰어난 FasterRCNN 이 mAP 54 인데 608x608 인풋을 사용한 YOLO 가 mAP 50 이다. 해당 모델의 Throughput (# of samples/second) 이 5.8 인데 반해 YOLO 는 104.5 이다. 그리고 두 모델의 overall mAP 는 둘다 37로 거의 동일하다. (GTX1070 기준으로 초당 104 장을 처리할 수 있다. 60fps 에서 608x608 이미지로 실시간 처리가 가능한 수준.)
그리고 동일한 모델에서 인풋 이미지를 416 으로 줄이면 속도를 220 으로 두배 올리면서도 mAP 는 1만 손해보면 된다. 여기서는 가장 균형잡혀 보이는 yolo3_darknet53_coco@416 모델을 사용했다.
모델 테스트
코드는 예제3 를 보면 알 수 있듯이 엄청 간단하다. utils 안에 있는 다양한 함수들(plot_bbox, plot_image 등)이 엄청 유용하다.
from timeit import time
from gluoncv import model_zoo, data, utils
from matplotlib import pyplot as plt
net = model_zoo.get_model('yolo3_darknet53_coco', pretrained=True)
utils.download('https://www.ctvnews.ca/polopoly_fs/1.4632164.1570679172!/httpImage/image.jpg_gen/derivatives/landscape_1020/image.jpg', path='market.jpg')
tic1 = time.time()
x, img = data.transforms.presets.yolo.load_test('market.jpg', short=320)
print(f'Shape of pre-processed image: {x.shape}, took: {time.time() - tic1:.3f} sec')
class_IDs, scores, bounding_boxs = net(x)
fig = plt.figure(figsize=(12, 10))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
utils.viz.plot_image(img, ax=ax1)
utils.viz.plot_bbox(img, bounding_boxs[0], scores[0],
class_IDs[0], class_names=net.classes, ax=ax2)
plt.show()
결과는 아래와 같다. i9 맥북프로에서 평균 0.45초 걸린다. 모든 작업을 MXNet 의 NDArray 로 비동기로 처리할 수 있다면 0.1 내외로 걸리겠지만 동기방식의 로직이 들어가는 순간 작업을 기다리게 되고 설명한대로 0.5초 내외로 걸리게 된다. (class_IDs 를 print 로 찍어보기만 하면 바로 알 수 있다)

YOLO 는 FCL(Fully Connected Layer) 가 없기 때문에 다양한 크기의 이미지를 입력받아서 처리할 수 있다. (대신 320, 416 처럼 32의 배수여야 하고, 추가로 논문의 의도를 생각해봤을땐 13x13 처럼 마지막 풀링 레이어가 끝났을 때 피쳐맵이 홀수로 구성되도록(416, 512, 608) 하는 것이 좋다.)
이런 이유로 인풋의 resolution 을 올려주기만해도 동일한 모델에서 더 나은 정확도와 느려진 속도를 경험할 수 있다. (CNN 계역에서 이미지 크기가 클수록 성능이 좋아진다는 것은 잘 알려져있고, 이미지 크기와 채널수, 모델 깊이 등의 상관관계를 최적화한 EffiecientNet5 같은 모델들이 있다.)
아래는 동일한 코드에 short 를 608 로만 바꿔준 결과이다. 오렌지, 바나나 등의 더 작은 물체들을 찾아내는 모습을 확인할 수 있다. 평균 1.57초 걸린다.

모델 최적화
시작하며 말했듯이 우리는 사람만 빠르게 찾는 모델을 만드는 것이 목표이다. 예제 코드에서 class_IDs 를 확인해서 사람이 아니면 드랍하는 방식으로 처리할 수 있다.
하지만 그보다 쉽고 효과적인 방법이 있다. 바로 net.reset_class() 를 이용하는 것이다.
튜토리얼중 하나에도6 나와있는데, 아래와같이 한줄만 추가해주면 지정한 클래스를 제외한 다른 클래스는 분류하지 않는다.
net = model_zoo.get_model('yolo3_darknet53_coco', pretrained=True)
net.reset_class(['person'], reuse_weights=['person'])
이후 사용방법은 동일하다. 위와 같이 reset_class 를 적용해주면 YOLO 의 경우 20% 정도 속도가 향상된다.
마치며
본업이 머신러닝 엔지니어도 아니고 해서 프레임워크를 딱 하나만 공부하고 싶었는데 MXNet 이 제격인 것 같다. (gluon 대신 keras 백엔드도 쓸 수 있지만 개인적으로는 딱히 필요할 것 같지는 않다.)
그리고 이미지 3개로만 테스트 했을때 ssd_512_resnet50_v1_voc 와 yolo3_darknet53_coco@512 를 비교하면 정확도는 비슷하고 속도는 SSD 쪽이 훨씬 빨랐다. MXNet 의 벤치마크 결과에 대한 신뢰도가 다소 의심되는 순간이었다. 실제 프로젝트에서도 SSD 를 반영해봐야겠다.