AWS X-Ray 로 로컬호스트에서 RDS 요청 추적해보기
2020년 05월 05일 작성TL;DR
코드는 여기1.
AWS 계정이 있다면 README.md 읽고 따라해볼 수 있다.
시작하며

REST 기반의 Stateless 서비스를(일반적인 웹서비스들) 여러개의 컨테이너로 관리할 때 가장 귀찮은 문제들이 아래의 2가지라고 생각한다.
- 퍼포먼스문제가 생겼을때 파악하기가 어렵다.
- 로드밸런서 덕분에(?) 컨테이너 별로 로그가 분산되어서 로그를 그룹화하기 힘들다.
이 글에서는 AWS X-Ray 를 이용해서 로컬 환경에서 위의 두 문제를 해결해본다.
문제정의
문제에 대해서 좀 더 구체적인 예를 보고, 거기에 맞춰서 문제를 해결해보자.
이 글에서는 RDBMS 기반으로 게시판을 운영한다고 가정한다.
퍼포먼스 문제
글을 가져오는 GET /posts 라는 요청은 DB 에서 다양한 정보(사용자 정보, 댓글정보, 관련된 추천 글 등) 를 가져와서 적절한 모양으로 가공한 뒤 반환한다.
로컬에서는 1초 내에 처리되던 요청이 K8S 컨테이너로 서빙을 했더니 속도가 10초가 걸린다.
로그를 각 구간별로 심어서 구간별 요청을 Percentile 로 구성한 뒤에 P95 이상의 구간에 대해서 느린 부분을 확인하고 싶다. (즉, 전체 요청의 95% 를 1초 이내에 처리하고 싶다.)
로그 그루핑
로그를 구간별로 출력하도록 로직을 추가했다고 하자.
수천개의 컨테이너가 로드밸런싱 되고 있는 상황에서 GET /posts 요청을 모아서 보기 위해서는 ELK 같은 중앙 집중형 로깅 시스템이 필요하다.
급하게 ELK 를 추가하기는 쉽지 않으니 (물론 AWS 를 쓴다면 가능하다 :D), 일단 특정 S3 버킷에 해당 요청에 대한 로그만 스트리밍으로 쌓기로 했다고 가정하자.
로그를 모아서 보다보니 특정한 패턴(기준)을 발견했다. 이 기준으로만 쌓인 로그를 따로 모아서 보고싶다.
샘플링
대량의 요청이 오가는 상황에서, 주요 로직이 아닌 로그에 대한 샘플링을 하지 않으면 엄청난 재앙을 만날 수 있다.
따라서 이런 위의 로그를 프로덕션 스테이지에 적용할 때는, 디버그 플래그 등으로 샘플링 기능도 추가하고 싶다.
주요 기능에 에러가 발생한경우 traceback 을 로깅하게 했는데, 로깅하는 과정에 문제가 있어서 최대 재시도 회수만큼 재시도 하면서 버퍼가 터진다던지…
인프라 배포
AWS X-Ray 를 이용하여 위의 문제들을 하나씩 해결해보자.
먼저 서비스 환경을 만들어보자. 서비스 환경을 만들기 위해 CDK 를 이용하여 실제로 리소스들을 AWS 위에 프로비전한다.
코드1 를 따라서 진행하면 리소스들을 배포할 수 있고, 해당 코드는 아래와 같은 아키텍쳐를 프로비져닝 한다.
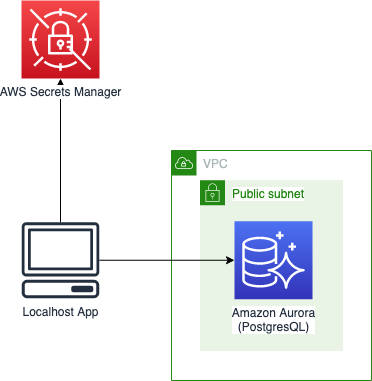
AWS X-Ray 에이전트 실행
ECS 나 EKS 등에서 AWS X-Ray 를 사용할때는 데이터를 직접보내는 것이 아니라 에이전트를 통해서 보내게 된다. X-Ray 에이전트는 UDP 통신으로 데이터를 받아서 AWS X-Ray 서비스로 전달한다.
X-Ray 에이전트는 보통 사이드카 컨테이너 형태로 실행하지만 여기서는 로컬호스트에 도커로 띄운다. (공식홈페이지에 나와있는 명령어는 Host 네트워크 모드를 사용하게 되어 있는데, X-Ray 에이전트는 Host 네트워크 모드로는 동작하지 않는다. 따라서 아래와 같이 도커의 기본 모드인 Bridge 모드를 사용한다.)
$ docker run \
--rm \
--attach STDOUT \
-v ~/.aws/:/root/.aws/:ro \
--name xray-daemon \
-p 2000:2000/udp \
amazon/aws-xray-daemon -o -n ap-northeast-2
App 실행
코드에서 제공하는 앱은 파이썬으로 작성된 간단한 게시판 앱 이며, 코드의 README 를 따라하면 쉽게 실행할 수 있다.
$ gunicorn src.app:api -b 0.0.0.0:8080
[2020-05-10 16:01:29 +0900] [67049] [INFO] Starting gunicorn 20.0.4
[2020-05-10 16:01:29 +0900] [67049] [INFO] Listening at: http://0.0.0.0:8080 (67049)
[2020-05-10 16:01:29 +0900] [67049] [INFO] Using worker: sync
[2020-05-10 16:01:29 +0900] [67068] [INFO] Booting worker with pid: 67068
INFO:botocore.credentials:Found credentials in shared credentials file: ~/.aws/credentials
app 로직 설명
src/app.py 에 API 요청을 처리하는 로직이 모두 포함되어 있다.
핵심 부분은 아래와 같으며 3개의 URL로 이루어져 있다.
api = falcon.API(middleware=[XRayMiddleWare(), ChaoticMiddleWare()])
api.add_route('/init', InitResource())
api.add_route('/posts', PostsResource())
api.add_route('/posts/{pid:int}', PostResource())
/init- 처음 RDS 가 실행되면 아무 테이블도 없기 때문에 posts 테이블을 생성(POST) 또는 삭제 해준다(DELETE)./posts- 글(post) 을 생성하는 작업. 글을 추가하면 RDS 의 posts 테이블에 레코드를 추가(POST)해준다./posts/{pid:int}- 개별 글에 대한 쿼리, 삭제 작업. posts 테이블에서 글을 가져오거나(GET) 삭제(DELETE)한다.
AWS X-Ray 코드 설명
먼저 X-Ray 는 큰 개념부터 순차적으로 트레이스 - 세그먼트 - 서브세그먼트 로 구성되어 있다.
- 각 요청은 트레이스 ID 에 의해 관리되고 하나의 트레이스 ID 는 여러개의 세그먼트를 가진다.
- 세그먼트는 한 서비스에 대한 모든 데이터 요소를 담고 있다. 한 세그먼트 내에서 다른 서비스로 나가는 요청은 서브세그먼트로 등록된다. 즉, 세그먼트는 여러 서브세그먼트를 가진다.
- 서브세그먼트는 하나의 세그먼트 안에서 다른 서비스로 나가는 요청의 개수만큼 추가될 수 있고, SQL쿼리문, 에러 상태등의 데이터를 포함할 수 있다.

위의 그림에서 API 에 해당하는 ScoreKeep 이 세그먼트이고, ScoreKeep 에서 Resources 로 나가는 화살표가 서브세그먼트 들이다.
각 세그먼트와 서브세그먼트에 데이터를 추가하는 방법으로 annotation 과 metadata 가 있다.
둘의 가장 큰 차이는 annotation 으로 데이터를 추가하면 해당 기준으로 그루핑이 가능하지만 metadata 로 데이터를 추가해주면 해당 기준으로 그루핑을 할 수 없다.
문제 시나리오별 기능
아래의 테스트는 httpie2 를 이용해서 진행한다. 아래의 명령으로 쉽게 설치 가능하다. httpie 는 curl 보다 사람이 관리하고 읽기 쉽게 쿼리를 보낼 수 있다.
$ pip install httpie
$ http get https://localhost:8080
퍼포먼스 확인 및 문제 구간 파악
POST /init 요청은 디비에 posts 테이블이 없으면 테이블을 추가해준다.
$ http post http://localhost:8080/init
HTTP/1.1 200 OK
Connection: close
Date: Sun, 10 May 2020 12:41:40 GMT
Server: gunicorn/20.0.4
content-length: 2
content-type: application/json
ok
동일한 요청을 한번 더 보내면, 해당 테이블이 이미 존재하기 때문에 에러를 발생시킨다.
아래 명령으로 해당 요청을 20번 정도 보내고 Ctrl+C 로 강제종료해보자.
$ while true; do sleep 0.1; http post http://localhost:8080/init; done;
HTTP/1.1 400 Bad Request
Connection: close
Date: Sun, 10 May 2020 12:43:53 GMT
Server: gunicorn/20.0.4
content-length: 49
content-type: application/json
vary: Accept
{
"title": "Error while connecting to PostgreSQL"
}
...
[X-Ray 콘솔 페이지]로 이동해서 사이드바의 Traces 메뉴를 보면 아래와 같은 화면을 볼 수 있다.
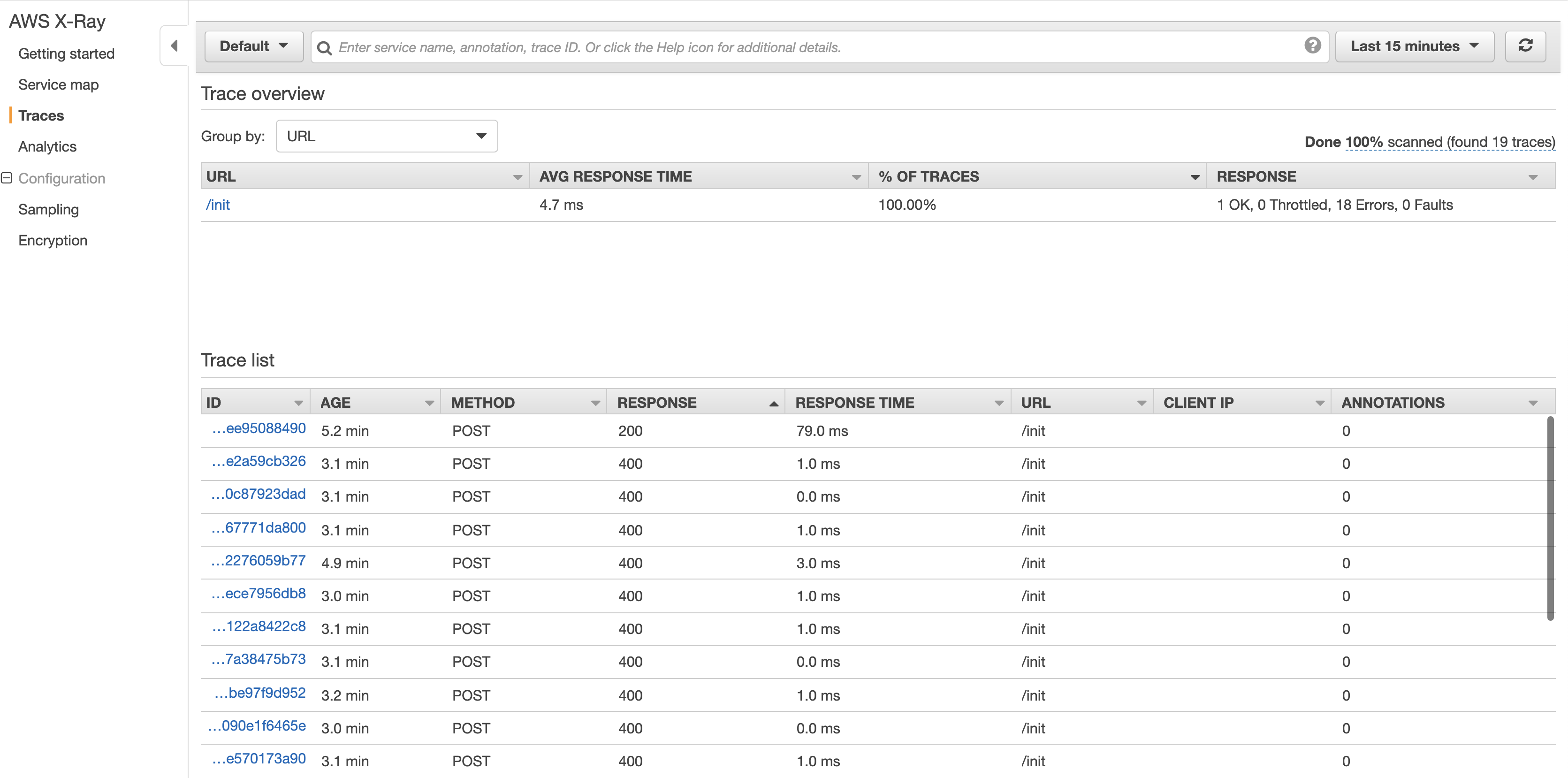
RESPONSE 를 보면 하나만 200 (정상처리) 이고 나머지는 전부 400 (에러) 인 것을 볼 수 있다.
200 에 해당하는 아이디를 클릭해보면 아래와 같은 트레이스 맵이 표시된다.
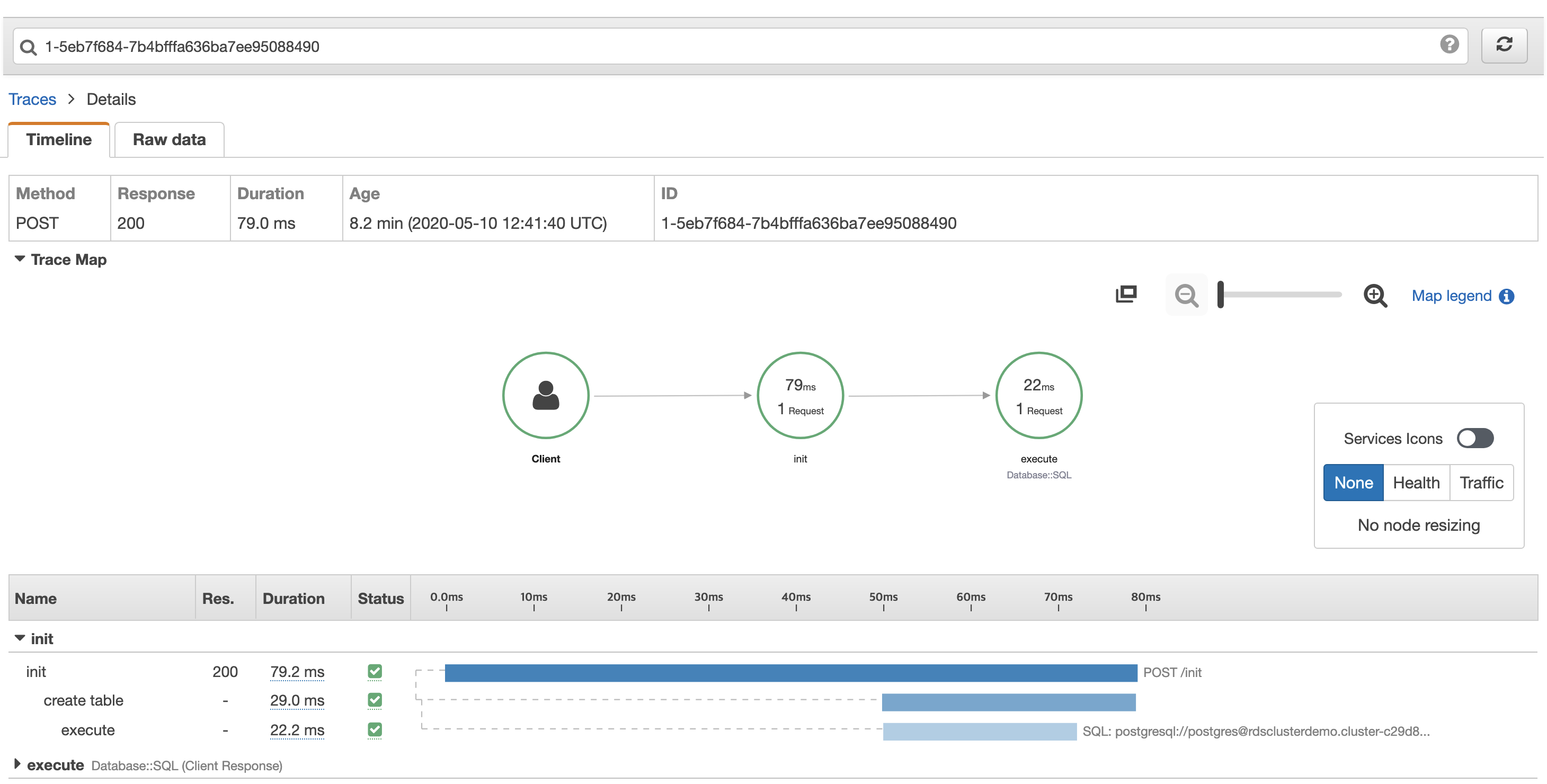
init 이라는 이름의 segment 에 create table, execute 2개의 서브세그먼트가 있는 것을 확인할 수 있다.
class InitResource(BaseResource):
def on_post(self, req, resp):
conn = self.get_conn()
with xray_recorder.in_subsegment('create table') as subsegment:
with conn.cursor() as cursor:
sql = """CREATE TABLE posts ( \
id serial PRIMARY KEY, \
username VARCHAR(256), \
title VARCHAR(256), \
content TEXT
);"""
cursor.execute(sql)
conn.commit()
subsegment.put_metadata('sql', sql)
xray_recorder.end_subsegment()
resp.status = falcon.HTTP_OK
resp.body = 'ok'
위의 코드는 init 호출 핸들러이며 create table 서브세그먼트에 sql 이름으로 실행한 쿼리명을 추가해둔 것을 확인할 수 있다.
콘솔에서 create table 을 선택한뒤 Metadata 탭을 선택해보면 아래처럼 metadata 가 정상적으로 쌓여있는 것을 확인할 수 있다.
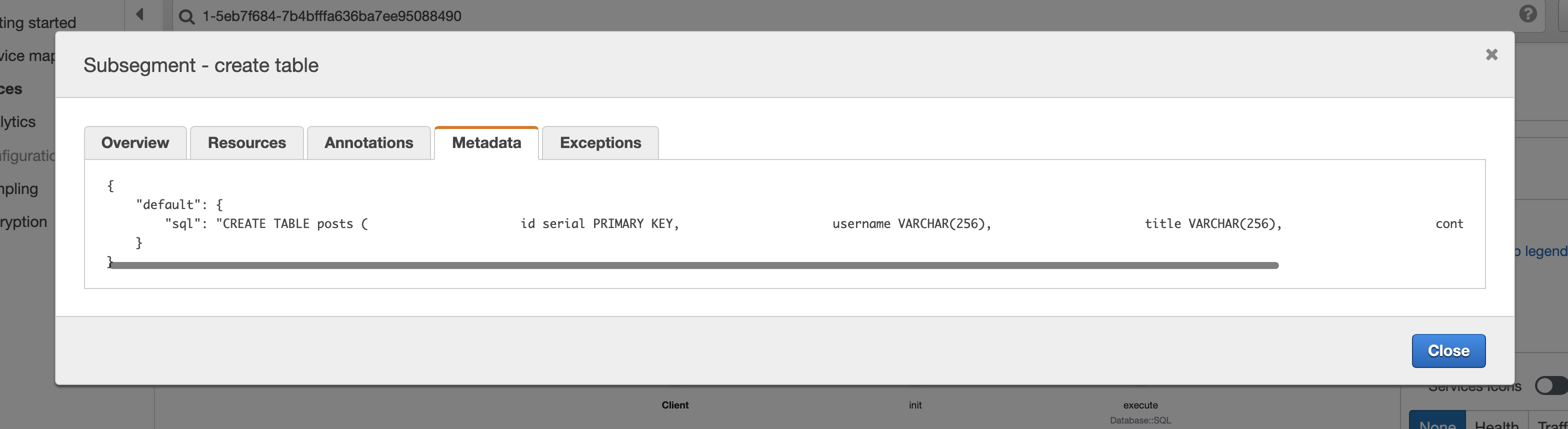
로그를 지정된 조건에 맞춰서 그룹화
로그를 특정한 조건에 맞춰서 확인하려면 annotation 기능을 이용하면 된다.
현재 글을 작성하는 POST /posts 기능은 아래와 같이 X-Ray에 데이터를 쌓고 있다.
req.context.segment.put_annotation('username', username)
conn = self.get_conn()
with xray_recorder.in_subsegment('create post') as subsegment:
with conn.cursor() as cursor:
sql = f"INSERT INTO posts (title, content, username) VALUES ('{title}', '{content}', '{username}'"
cursor.execute(sql)
conn.commit()
subsegment.put_metadata('sql', sql)
이렇게 put_annotation 으로 데이터를 쌓으면 콘솔화면이나 API 를 통해 username 으로 그루핑해서 로그들을 확인할 수 있다.
POST /posts 요청을 통해 15개의 글을 작성해보자.
#!/bin/sh
SET=$(seq 1 15)
for i in $SET; do
http post http://localhost:8080/posts username="haandol" title="haandol$i" content="haandol$1"
http post http://localhost:8080/posts username="haandol" title="haandol$i" content="haandol$1"
sleep 0.5
done
위의 커맨드로 글을 추가하고 콘솔을 가보면 15개의 트레이스 목록이 추가된 것을 확인할 수 있다.
상단에 있는 필터입력창에 annotation.username = "haandol" 를 입력하면 해당 annotation 으로 추가된 요청만 따로 볼 수 있다.
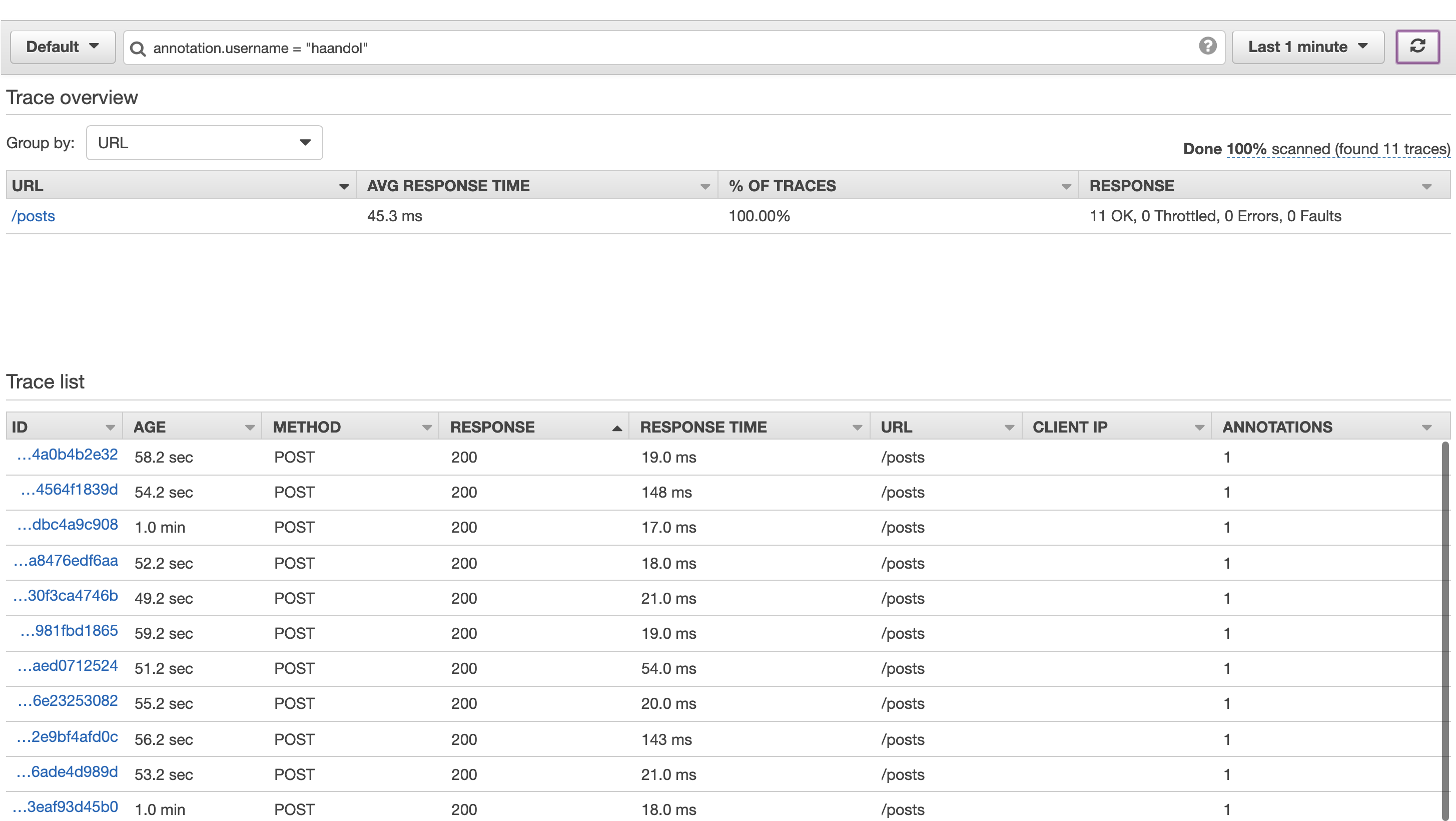
샘플링
X-Ray 는 여러개의 샘플링 룰을 지정해두고 사용할 수 있게 해준다. 코드에서는 아래와 같이 꺼둔 상태이지만,
xray_recorder.configure(
sampling=False,
service='xray-tutorial',
daemon_address='localhost:2000',
)
프로덕션 스테이지에서는 아래와 같은 형태로 샘플링룰의 경로를 지정해서 사용하게 된다. 샘플링기준은 초당 고정개수, 고정비율 등으로 리밋을 제어할 수 있고, URL 주소 등으로 필터링을 추가할 수도 있다.
xray_recorder.configure(sampling_rules='./get_posts_rule.json')
get_posts_rule.json 파일 내용
{
"version": 1,
"rules": [{
"description": "Get Posts",
"service_name": "xray-tutorial",
"http_method": "POST",
"url_path": "/posts/*",
"fixed_target": 0,
"rate": 1
}],
"default": {
"fixed_target": 0,
"rate": 1
}
}
마치며
AWS X-Ray 를 이용하면 대규모 서비스를 운영할 때 반드시 필요한, 분산트레이싱을 쉽게 구현할 수있다.
ECS 나 EKS 에서 X-Ray 를 사용하는 경우 에이전트를 사이드카로 지정해주는 것 외에는 본 글의 내용과 동일하며, 람다는 에이전트가 필요하지 않다.