API Gateway 를 이용한 클릭스트림 로깅
2020년 07월 28일 작성TL;DR
코드는 여기1.
시작하며
AWS 위에서 로깅을 어떻게 쌓아두고 분석할지에 대한 가이드를 찾는 사람이 꽤 많다.
로깅하는 데이터의 형태와 저장소는 로그를 사용하는 목적에 따라 달라지기 때문에 정답은 없다. 비용과 속도를 적절히 트레이드오프 해가면서 최적의 비용으로 처리하면 그만이다.
시스템 모니터링 목적이라면 Cloudwatch 와 Cloudwatch Logs Insights 정도면 충분하다. Cloudwatch 는 알람기능도 제공하기 때문에 별다른 설정없이 운영에 필요한 정보를 얻고 행동을 할 수 있다.
하지만 비즈니스 로직이나 사용자 행동분석 등의 인사이트를 위해서는, 중간과정이 어찌되었든 S3 로 쌓아서 Athena 나 EMR 등으로 결과를 분석해야 한다.
직접 경험했던 나름 대규모의 서비스에서는 아래 2가지 방식으로 비즈니스 매트릭이나 사용자의 행동을 로깅 했다.
-
nginx/haproxy 등의 리버스 프록시(겸 LB) 를 이용해서 표준화된 로그형태로(apache format) 파일로 쌓고, 에이전트를 이용하여 로그파일을 읽어 ELK(or EFK) 스택에 쌓아서 분석한다.
-
MSA 와 이벤트드리븐 아키텍쳐를 사용시, 오가는 모든 이벤트(대부분 이벤트는 json 형태)를 S3에 적재해둔다.
-
CloudWatch 에 json 으로 로그를 다 쌓아두고 Cloudwatch 에 쌓인 로그를 S3 로 export 해서 적재해둔다.
그러나 위의 세 경우는 기존에 뭔가 서비스를 운영하고 있던 입장에서는 고쳐야할 부분이 많을 것이고 로그 시스템과 서비스 시스템이 완전히 결합되는 것도 맘에 들지는 않는다. (로그가 폭주해서 서비스가 망한다거나, 서비스 부하가 심해져서 로깅이 누락된다거나)
클라우드를 쓰면서 로깅 시스템을 새로 구성해서 처리하는 것이 큰 부담은 아니게 되었다. 오히려 다른 서비스들과의 강결합을 끊어서 구조적으로도 깔끔해지고 계정을 다르게 구성해주면 계정단위의 limit 에 대한 부하도 줄어든다.
그래서 최근에는 로깅 시스템을 따로 두고 클라이언트나 서버에서 로깅이 필요한 경우 비동기로 요청을 보내고 잊어버리는 식의 구성을 자주 사용했었다. (fire & forget)
이번 글에서는 API Gateway 를 이용하여 F&F 방식으로 로깅하는 시스템을 살펴본다.
아키텍쳐
코드1 를 provision 하면 아래와 같은 아키텍쳐가 개인 AWS 계정에 프로비젼 된다.

빌딩블록 역할
메인 블록은 API Gateway, Kinesis, Firehose, S3 이다. 분석용 블록인 Athena 와 Crawler 는 코드에 포함되어 있지 않기 때문에 넘어가자.
- API Gateway 는 지정된 url 로(코드에서는 /) 들어온 모든 요청을 적절히 가공해서 Kinesis 로 전달한다.
- 여기서는 Kinesis 는 데이터를 그대로 Firehose 로 전달하는 역할만 한다. API Gateway 를 Firehose 에 바로 연결할 수도 있지만, 이 경우 RPS(Requests Per Second)가 Firehose 의 Limit 에 도달하는 등의 문제가 생기면 로그가 날아가버리는 문제가 생기기 때문에 중간 저장소로 Kinesis를 둔다.
- Firehose 에서 바로 S3 로 내보내지 않고 Lambda 를 통해서 내보내는 것은 Firehose 가 데이터를 S3 로 적재할때 바로 이어붙여서 내보내기 때문에, 개행문자(\n) 를 넣어주기 위해서이다. 개행문자가 없이 여러개의 json 을 이어붙여서 내보내면 Athena Crawler 에서 처음 한개만 읽고 이후 데이터를 읽지 못한다. (직접 쿼리를 구현해서 json decoder 등으로 처리할 수도 있으므로, 쿼리타임에 비용을 쓰느냐 적재할때 비용을 쓰느냐 차이이다. 개인적으로는 소규모 데이터를 다루는게 더 편하고, 분석쿼리 시간을 줄이는 것이 비용상 훨씬 유리하다.)
- S3 에 적재될때는 대상 버킷에
/2020/07/28/13/ClickStreamXYZ식으로 쌓이기 때문에 Athena 에서 처리하기 편하다.
사용방법
설치는 코드의 README 에 있으므로 넘어간다.
로그 쌓기
/ url 에 POST요청으로 데이터를 보내면 해당 parameters 와 body 데이터가 위의 파이프라인을 통해 S3 로 적재된다.
여기서는 아래와 같은 데이터로 10번정도 요청을 보내본다.
http post https://bus1cqfmhh.execute-api.ap-northeast-2.amazonaws.com/dev/\?path\=/items/323\¶m1\=value1\¶m2\=value2 text=hihi dodo=dada
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 133
Content-Type: application/json
Date: Tue, 28 Jul 2020 05:51:04 GMT
X-Amzn-Trace-Id: Root=1-5f1fbcc8-1b10bf3009b4beb5be8e71e3
x-amz-apigw-id: QXpvSHhjIE0FQXw=
x-amzn-RequestId: acb1a6cb-c274-4500-8e63-d2ae7b287588
{
"EncryptionType": "KMS",
"SequenceNumber": "49609285576784916227761242557547914691804454865145430018",
"ShardId": "shardId-000000000000"
}
S3 로그 확인
60초를 기다리거나 요청을 더 많이 보내면 S3 에 데이터가 보이게 된다.
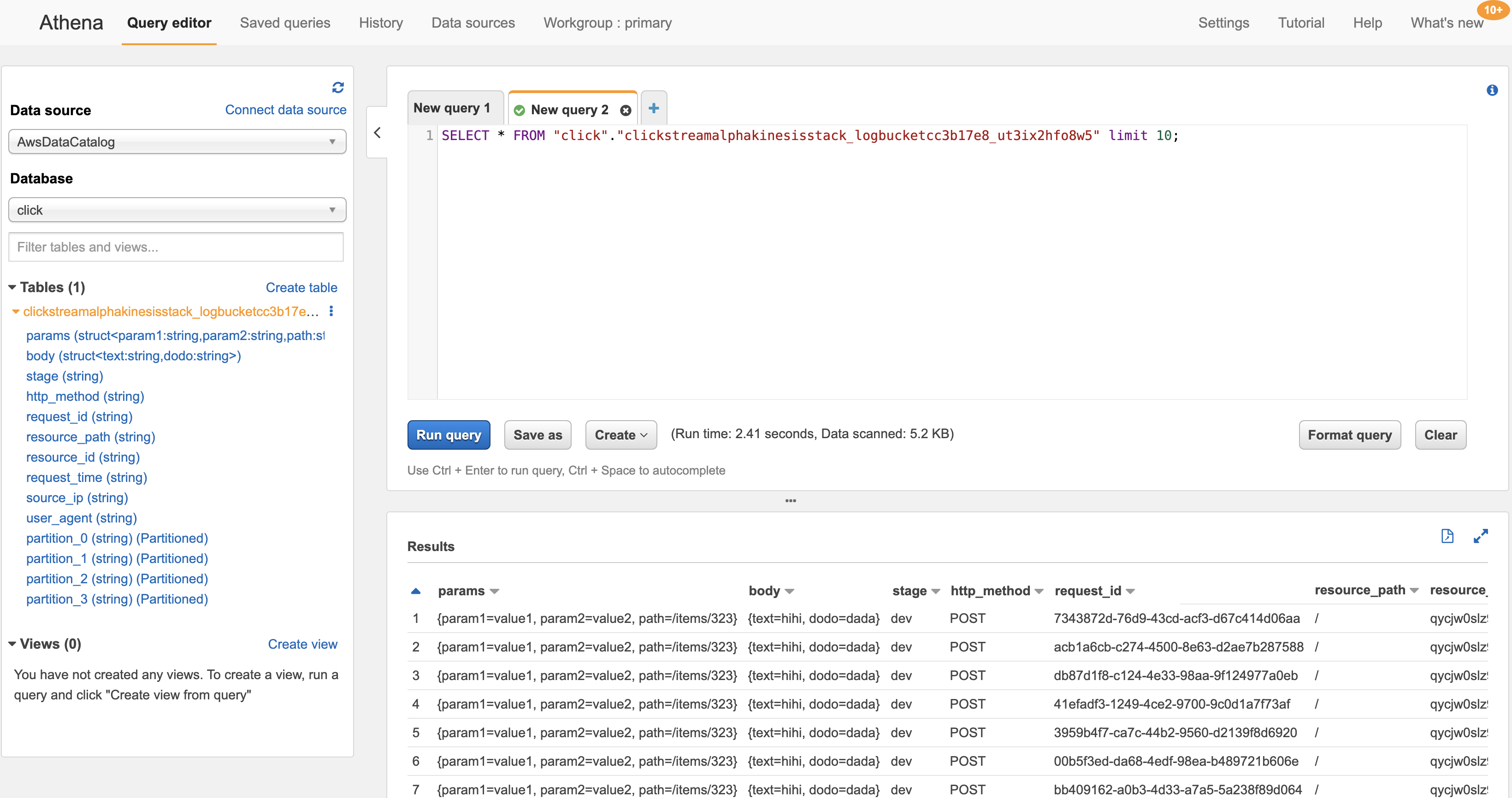
데이터 내용은 대략 아래와 같을 것이다.
{"params": {"param1": "value1","param2": "value2","path": "\/items\/323"},"body": {"text":"hihi","dodo":"dada"},"stage": "dev","http_method": "POST","request_id": "acb1a6cb-c274-4500-8e63-d2ae7b287588","resource_path": "/","resource_id": "qycjw0slz9","request_time": "28/Jul/2020:05:51:04 +0000","source_ip": "54.239.119.16","user_agent": "HTTPie/2.1.0"}
...
{"params": {"param1": "value1","param2": "value2","path": "\/items\/323"},"body": {"text":"hihi","dodo":"dada"},"stage": "dev","http_method": "POST","request_id": "d57b413f-8398-4ef7-88cd-ef6cd025f22d","resource_path": "/","resource_id": "qycjw0slz9","request_time": "28/Jul/2020:05:51:19 +0000","source_ip": "54.239.119.16","user_agent": "HTTPie/2.1.0"}
Athena 로 쿼리하기(옵션)
이제 S3 에 적재된 JSON 데이터를 이용하여 다양한 작업을 할 수 있다.
여기서는 Athena 를 이용하여 간단한 쿼리를 날리는 법을 알아보자.
-
Glue 서비스 페이지로 이동한다.
-
Databases -> Add database 를 클릭해서 데이터베이스를 생성한다.
-
Athena 서비스 페이지로 이동한다.
-
Query Editor -> Tables -> Create Table 을 클릭하고 뜨는 팝업창에서 from AWS Glue Crawler 를 선택한다
-
크롤러를 생성해준다. 기본값으로 생성하면 되며, 어려운 내용이 없으므로 생략한다. S3 위치 선택할때 아래와 같이 최상위 위치를 선택해주는 것만 주의하자.
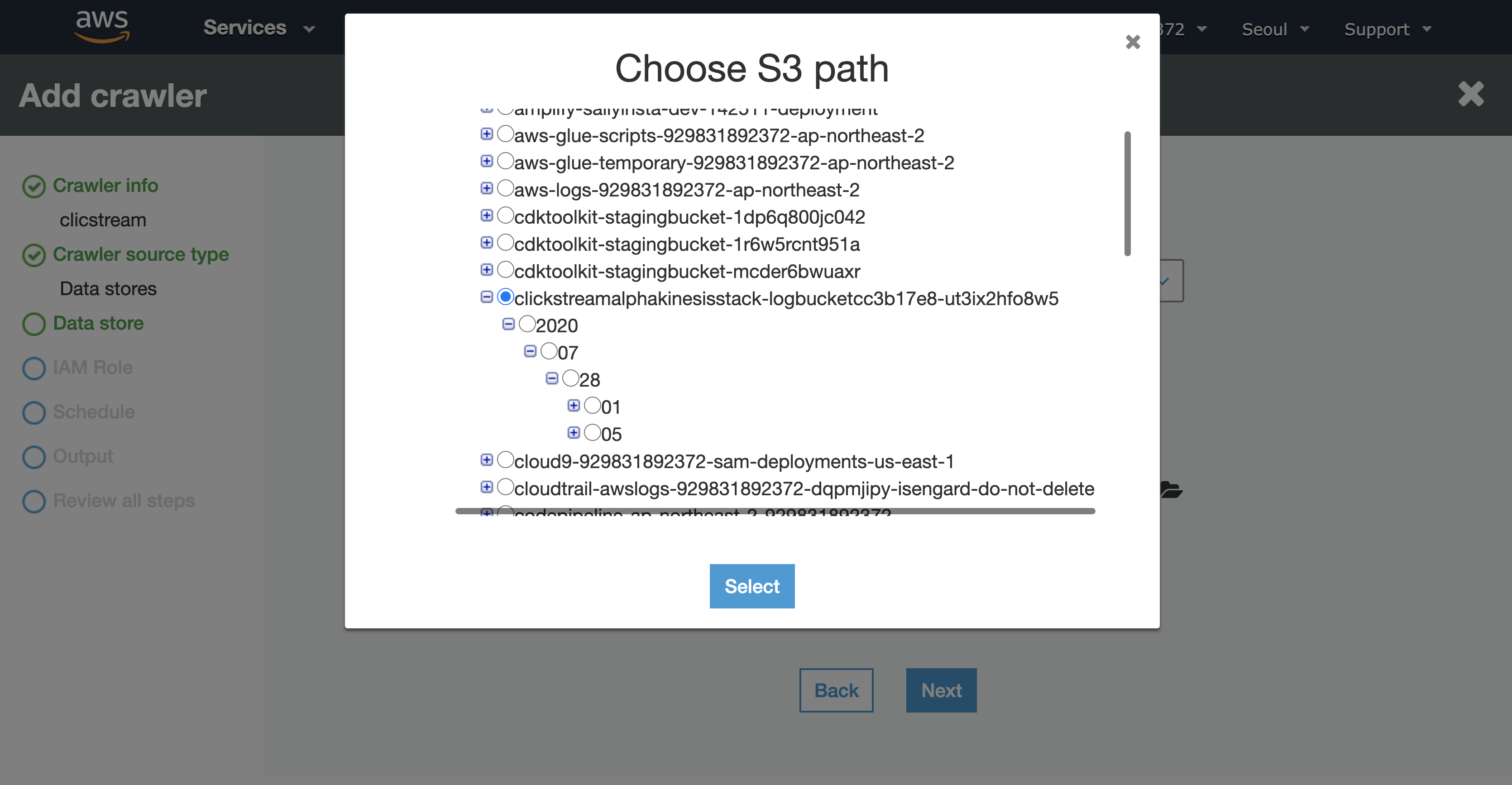
-
생성된 크롤러를 Run crawler 해주면 1분정도 크롤러가 돌고나서 테이블이 생긴다.
-
Athena 서비스 페이지로 다시 이동하여 테이블이 표시되는지 확인하고 쿼리해본다.
마치며
이 서비스를 프로덕션에 적용하려면 아래와 같은 내용을 고려해서 서비스 쿼타를 늘려야 한다.
- API Gateway 는 5000 rps 가 기본이므로 상회하는 요청에 대해서는 서비스 쿼타를 늘려줘야한다.
- Kinesis는 샤드당 1000 rps 처리할 수 있으며 사용량이 늘어나면 샤드를 늘려주면 된다.
- Firehose 는 Kinesis 가 소스스트림일 경우에는 처리량에 대해 신경안써도 된다. DirectPut 으로 직접 입력하는 경우에는 1000 rps 가 기본 제한이다.
- 람다는 폴링으로 처리되기 때문에 Firehose 의 버퍼크기와 버퍼대기시간에 영향을 받는다.