KoGPT2 로 Amazon Lex 같은 다이얼로그 기반의 챗봇 만들기
2021년 07월 25일 작성TL;DR
코드는 여기1
시작하며
다이얼로그 기반의 한글 챗봇을 쓸 일이 생겼는데, Amazon Lex 는 한글지원이 안된다.
Rasa, Watson, Lex 같은 다이얼로그 기반의 챗봇 아키텍쳐들을 이것저것 뒤져봤는데, 머리가 나빠서 이해가 잘 안되었다..
그래서 NLP 공부하면서 Amazon Lex를 단순화 시킨 챗봇 프레임워크를 하나 만들어봤다.
(개인적으로는 프로덕션에서 쓴다면 구글의 다이얼로그플로우를 쓸 것 같다.)
아키텍쳐
일단 챗봇의 아키텍쳐는 대부분 아래와 같은 구조로 되어 있다.

- 사용자가 입력한 문장을
NLU(자연어처리유닛)가 받아서 적절한 처리를 한 뒤에 - 적절한
Intent(의도)를 찾아낸다. 만약 의도를 찾을 수 없다면FallbackIntent로 처리된다. - 다이얼로그 매니저는 사용자의 의도를 처리하기 위해 필요한 정보들을 다시 사용자로부터 입력받는다. 이때 필요한 정보를 보통
Slot이라고 부른다. (위 그림에서는 Entity) - 의도를 처리하기 위한 슬롯들이 다 채워졌다면(fulfilled)
- 필요에 따라 사용자로부터 최종적으로 확인을 받거나, 그냥 의도를 종료처리한다.
그리고 Lex 는 다음과 같은 구조로 되어 있다.
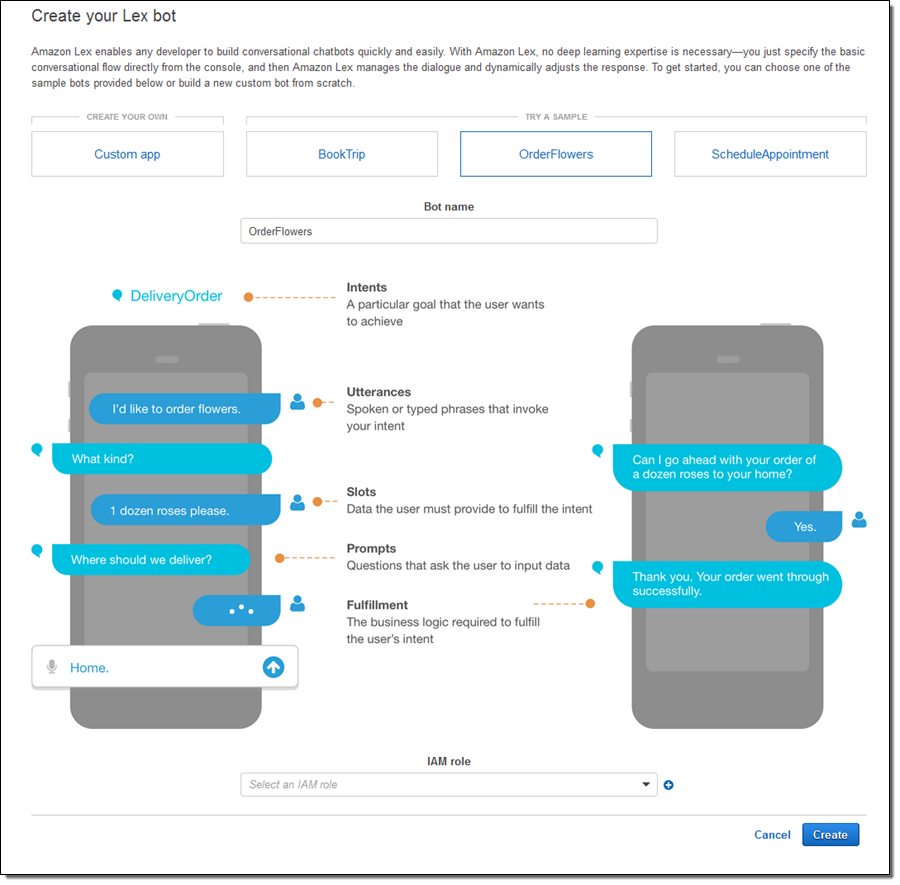
- Intent
- Utterances
- Slots (and SlotTypes)
- Prompts
- Fulfillment
Lex 는 한글이 안되서 써본사람은 별로 없겠지만, 대략 위에서 설명한 챗봇 아키텍쳐랑 크게 다르지 않은 구조를 가진다.
구현설명
코드의 구조는 Lex 의 흐름을 그대로 가져다 만들려고 했기 때문에 코드 자체를 설명할 건 별로 없다.
그래서 본 글에서는 코드에 대한 모든 설명보다 주요 컴포넌트의 구현방향과 개선방향을 간단히 적어본다.
nlu.py & dialog.py
NLU는 사용자의 입력테스트와 인텐트의 예제텍스트들간 유사도를 측정할 수 있도록 자연어를 피쳐로 변환해준다.
자연어처리는 다양한 방법으로 구현할 수 있지만, 프로토타이핑 정도로 만들거기 때문에 여기서는 정확도를 희생하고 가장 쉬워보이는 방법으로 구현했다.
현재 구현 형태는 아래와 같은데, huggingface 의 기학습된 kogpt2 언어모델을 그대로 사용했다.
intent 는 대략 이렇게 생겼다.
intents:
- name: flower
utterances:
- 꽃을 사고 싶습니다
- 꽃을 사고 싶다
- 꽃 내놔
- 꽃이 필요해
- 플라워가 필요해
- 플라워를 사고 싶다
fulfill_prompt: '감사합니다. 주문이 완료되었습니다.'
reject_prompt: '아쉽군요. 꽃 주문을 취소하겠습니다.'
이 인텐트를 처리하기 위해 사용자의 입력문장을 매핑하는 과정은 다음과 같다.
- Intent 에 미리 입력된 utternaces 을 언어모델에 넣고 다음 단어들을 예측해서 가지고 있는다.
- 사용자 입력문장을 언어모델에 넣고 다음 단어들을 예측한다.
- Intent 의 utternaces 로 예측된 단어들과 사용자 입력문장으로 예측된 단어들을 cosine_similarity 를 이용하여 유사도를 측정한다.
- threshold 이상의 유사도를 보이면 입력문장을 해당 Intent 로 분류한다.
단순직관을 이용한 아이디어이기 때문에 정확도가 높지 않겠지만, 언어모델이 아니라 QA 모델을 쓰거나 언어모델에 도메인 데이터를 더 넣어주면 정확해질지도 모르겠다.
NSMC 처럼 인텐트 별로 파인튜닝된 모델을 사용하면 정확도가 훨씬 높아 질 것이다.(인텐트 분류기처럼 동작하도록) 하지만 Lex는 파인튜닝 과정이 없이 인텐트를 잘 잡아낸다. 임의의 인텐트를 쉽게 추가하려면 언어모델을 사용했으리라고 추측했고, 언어모델을 그대로 사용해보니 봐줄만하게 동작하는 것 같았다.
제대로 품을 들여서 만든다면 KoNLPy 등으로 핵심명사를 먼저 뽑아내고 (다이얼로그 특성상 처음 보는 단어는 없다고 가정할 수 있다. 정확히는 처리하지 않는다고 할 수 있지만..) 해당 명사와 동의어를 찾아내서 동의어들도 처리하게 해주는 것이 좋을 것이다. 이 부분도 역시 GPT2를 NER 로 파인튜닝해서 사용할 수 있다.
그리고 사용자의 동사가 트리거 동사들(꽃 구매의 경우 사다, 보다)일 경우에 해당 인텐트를 시작해주는 식으로 동사도 함께 볼 수 있다.(stemming 을 해줘야 할 것 같다.)
slot.py & slot_type.py
인텐트를 처리하기 위해 필요한 정보를 정의하는 것이 슬롯(Slot)이고 이 슬롯의 값을 정의하는 것이 슬롯타입(SlotType)이다.
슬롯과 슬롯타입은 아래와 같이 생겼다.
slots:
- intent_name: flower
values:
- name: kinds
type: flower_kinds
prompt: "무슨 종류의 꽃을 사고 싶으신가요?"
- name: pickup_date
type: date
prompt: "몇월 며칠에 {kinds} 을(를) 픽업하실 건가요?"
- name: pickup_time
type: time
prompt: "{pickup_date} 몇시 몇분에 {kinds} 을(를) 픽업하실 건가요?"
- name: confirm
type: confirm
prompt: "좋습니다. {pickup_date} {pickup_time}에 {kinds} 꽃을 준비해두면 될까요?"
----
slot_types:
- name: flower_kinds
values:
- 장미
- 백합
- 할미꽃
Lex 에서는 2종류의 슬롯타입을 지원한다.
- 사용자가 값을 지정해두고 해당 값들에 매핑하는 커스텀 슬롯타입
Amazon.DATES같은 형태로 빌트인 슬롯타입
위의 flower_kinds 는 커스텀 슬롯타입이고, date, time 은 빌트인 슬롯타입이라고 볼 수 있다.
커스텀 슬롯타입의 경우 대충 만들어서 현재는 완전 일치하지 않으면 해당 슬롯을 다시 채우게 시도하는데, Lex 의 경우처럼 대략 일치하면 채워지게끔 고쳐도 좋을 것 같다. 빌트인 슬롯타입도 대충 만들었는데, 제대로 만들면 훨씬 정교하고 예외에 강건하게 만들 수 있을 것이다.
람다에서 돌려보기
코드의 README.md 에 적어두었지만 람다에서 돌려볼 수 있다.
도커이미지는 대략 4G 정도 나오는데 GPT2 모델크기가 커서 그렇다.
(3GB 램 기준으로 첫 호출은 20초 후반에서 30초이상 걸릴때도 있다. 메모리를 크게 할당하든, 모델을 좀 작은걸 쓰든, 프로비전컨커런시를 걸어서 쓰든, 비동기로만 쓰든 해야할 것 같다..)
마치며
NLP 를 이번에 처음 공부한거라 NLP 모델을 쓰면서 익숙해질 겸 한번 챗봇을 만들어봤는데 만들다보니 NLP 모델보다 그냥 코딩이 많아졌다…