쉽게 설명한 옵저버빌리티와 오픈텔레메트리 - 1/2
2021년 11월 30일 작성TL;DR
옵저버빌리티(Observability)는 아래 3개의 핵심 구성요소(pillars)를 가진다.
- Metrics
- Logs
- Traces
위의 3개가 모두 다 갖춰져있어야 시스템이 Observable 하다고 부를 수 있다.
시작하며
다시 프로덕션 시스템을 개발해야 하는 상황이 오면서, 예전에 소프트웨어 엔지니어로써 가장 힘들었던일이 뭐였나 생각해보니 디버깅이었다.
기존 시스템은 이벤트 드리븐 아키텍쳐를 쓰고 있었고 트랜잭션을 choreography 방식으로 처리하고 있었다.
각 이벤트에는 parent 이벤트 정보만 담고 있어서 여러단계의 서비스를 거치는 에러가 났을때 디버깅하기가 어려웠다.
또, 적절한 메트릭(e.g. p99 latency)이나 메트릭 목표(e.g. <1s)가 없어서 시스템에서 사용자 경험에 대한 추적이 어려웠다.
이러한 모던 아키텍쳐 기반의 시스템은 서비스에 필요한 모든 정보를 쌓고 적시에 어렵지 않은 방법으로 조회할 수 있도록 미리 시스템을 구축해두는 것이 매우 중요한데,
이 시스템에 대한 내용들을 잘 정리해둔 것이 옵저버빌리티(Observability) 라고 할 수 있다.
본 글에서는 옵저버빌리티에 대한 기본적인 내용들을 간단히 정리하고,
다음 글에서는 오픈텔레메트리를 간단한 예제와 함께 살펴보자.
Observability Overview
언제 옵저버빌리티가 필요한가?
처음 프로덕션 서비스를 운영하면 다운타임으로 인한 온콜을 최소 한번 이상 겪게 된다.
서비스 카테고리별로 다운타임에 대한 의미가 다르겠지만, 특히 리테일 서비스는 다운타임이 매출과 직결되므로 이를 최소화하는 것이 매우 중요하다.
다운타임은 문제발생 - 인지 - 원인분석 - 문제해결 - 배포1 의 단계를 거쳐서 해결이 된다.
보통은 이 전체 단계를 MTTR1 이라는 시간단위로 관리하게 되며, 이 중 문제발생 - 인지 단계까지 걸리는 시간은 따로 MTTI1 라고 부른다.
이 내용을 풀어서 써보면 아래와 같은데,
- 현재 서비스가 정상인지 비정상인지 판단할 수 있는 기준을 가지고 있고,
- 비정상 상황 발생시 목표 시간내에 인지할 수 있으며
- 목표 시간내에 비정상의 원인(Root Cause) 를 찾아낼 수 있고
- 목표 시간내에 해당 원인을 수정해서 서비스를 정상화 시킬 수 있다면
위의 4가지를 다 할 수 있을 것 같다면 내가 다루는 시스템은 옵저버빌리티를 가지고 있는 상태이다.
반면에 매번 다운타임마다 위의 4가지 중 하나 이상에 대해 문제를 겪고 있다면 옵저버빌리티가 필요한 상태라고 볼 수 있다.
옵저버빌리티의 핵심 구성요소(Pillars)
옵저버빌리티는 아래의 3개의 핵심 구성요소로 분류할 수 있다.
- Metrics
- Logs
- Traces
각각에 대한 특징을 간단히 살펴보고 넘어가자
Metrics

메트릭은 문제가 발생했을때 가장 극적으로 변경되는 부분인 시스템의 상태를 표시해준다.
메트릭은 물리적인 기기의 리소스를 나타태는 시스템 메트릭과 그외에 사용자가 지정한 커스텀 메트릭으로 나눌 수 있는데,
시스템 메트릭은 CPU 사용량, 메모리 사용량, 하드디스크 남은 용량, 디스크 I/O, 네트워크 I/O 가 대표적인 예로,
클라우드를 쓰고 있다면 이러한 시스템 메트릭은 클라우드 시스템에서 무료로 수집해주며, 커스텀 메트릭도 약간의 코드 수정과 적은 비용으로 쌓을 수 있다.
EKS, ECS 같은 컨테이너 기반의 서비스를 쓸 경우에는 일반적으로 Agent 같은 사이드카를 이용하여 개별 컨테이너의 메트릭도 쌓게 된다.
Logs
logger.debug('@@@ I got here')
로그는 설명이 필요 없을정도로 개발자에게 친숙하다.
클라우드 환경에서는 stdout/stderr 으로 출력하면 클라우드워치와 같은 로깅시스템에서 확인할 수 있다.
보통 로그로 출력하는 내용들은 비즈니스 로직상 의미를 담고 있는 내용들이 많기 때문에, 다운타임 발생시 원인분석을 위해 로그의 출력 내용을 검색할 필요가 있다.
따라서 대부분의 시스템에서는 검색이 용이하도록 구조화된 형태2로 로그를 쌓게 된다.
AWS 에서는 JSON 형태로 구조화된 로그를 쌓는 것을 권장하는데, 이렇게 JSON 형태로 쌓으면 클라우드 워치에서 다양한 필터를 통해 여러 서비스의 로그를 한번에 검색할 수 있게 된다.
하지만 로컬에서 개발할때도 JSON 이 출력되면 엄청 귀찮기 때문에, 일반적으로 환경변수 등으로 플래그를 줘서 로컬환경일때는 평문으로 출력이 되지만 배포된 환경에서는 JSON 으로 출력되도록 해둔다.
Traces
특정 사용자의 요청이 아래와 같이 이벤트로 전달되어 처리된다고 하자.
사용자 -> API Gateway -> 서비스 A -> 서비스 B -> 서비스 C
서비스 C 에 에러로그가 생겼다면 이것을 요청한 사용자와 어떻게 매칭할 수 있을까? 해당 로그와 관련된 서비스들의 로그들을 어떻게 한번에 볼 수 있을까?

위와 같이 하나의 리퀘스트가 여러 서비스에 분산되어 처리될때, 특정 리퀘스트를 기준으로 연관된 로그들(또는 메트릭들)을 모아서 볼 수 있게 해주는 것이 트레이싱이라고 할 수 있다.
각 트레이스는 트레이스 ID 라는 것을 가지고 보통 리퀘스트 ID 를 트레이스 ID 로 지정하거나 매 리퀘스트 시작시 트레이스 ID 를 새로 만들어서 모든 서비스간 호출에 전달해준다.
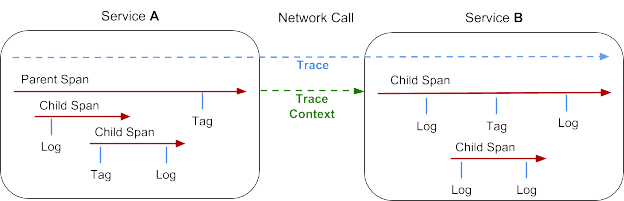
자세한 내용은 다음글에서 설명하겠지만, 위 그림과 같이 트레이스는 하나 이상의 스팬(Span) 을 가지게 되며 각 Span 은 다시 하나 이상의 Span 을 가질 수 있다.
그리고 이 스팬들이 담고 있는 정보들을 컨텍스트(Context) 라고 부른다.
트레이스는 여러개의 서비스에서 생성한 스팬들을 모아서 하나로 보여주는 것이 목표이기 때문에,
각 서비스의 자신의 컨텍스트를 다른 서비스로 전달해야 하고, 이렇게 서비스간 컨텍스트 전달을 통해 트레이스ID 를 유지하는 것을 컨텍스트 전파(Context Propagation) 이라고 한다.
Observability 를 적용하는 방법
옵저버빌리티를 시스템에 적용하려면 어떤 단계를 거쳐야 하는가?
- 이상/비이상 상황을 판단하는 기준을 세운다.
- MTTR / MTTI 기준을 세운다.
- 해당 기준을 체크할 수 있는
트레이싱 - 메트릭 - 로그환경을 구축한다.
기준점 - SLI/SLO
이상 / 비이상 상황을 판단하는 기준으로 많이 사용하는 것이 SLI/SLO3 이다.
비교적 단순한 SLO 인 엔드유저가 서비스A 를 호출할 때의 p99 latency 를 T초 이내로 한다 를 예로 들어보자.
2016년 구글 연구결과 리테일에서 5초 이내로 로딩 되는 모바일 사이트가 19초만에 로딩되는 모바일 사이트보다 2배의 광고효율이 나왔다고 한다.
하지만 최근에는 LTE 가 상용화되면서 사이트 로딩에 19초가 걸리면 기다리는 사람은 별로 없을 것이다. 5초도 안기다리는 사람도 꽤 있을 것이다.
반면 서비스C가 배치로 호출하는 서비스B의 API /batch는 각 엔트리를 T초 이내로 완료해야한다. 를 예로 들면,
이 경우 T초는 서비스B 의 특성을 고려하거나 전체 배치의 처리속도를 고려해서 설정해야 하겠지만, 확실한건 첫번째 예제보다 훨씬 유연한 기준을 가질 수 있다는 점이다.
이렇듯 SLI/SLO 는 서비스의 특성에 따라 설정하되, 주변 환경이나 비즈니스 요구사항에 따라 지속적으로 바뀔 수 있다.
MTTI/MTTR
MTTI를 줄이는 것은 상대적으로 쉽다. 적절한 기준을 정하고 알람을 설정해두면 된다.
예를 들어, API A의 최근 1시간 에러율이 10% 를 넘는 경우 알람 등의 기준을 세우고 해당 알람을 설정한 뒤, 메일, 슬랙 또는 pagerduty 같은 툴로 실시간으로 알려주면 된다.
반면 MTTR 은 상대적으로 더 까다로운데, 장애를 인지하고 나서(MTTI) 해결하기 위해서의 전체과정이 포함되기 때문이다.
일반적으로 장애 발생시 아래의 순서로 해결을 진행할 것이다.
- 트레이스들을 살펴보고
- 해당 트레이스들에서 발생한 에러들을 Span 단위의 로그를 통해서 확인하고
- 경우에 따라 해당 시점의 Metric 도 살펴본다.
- 문제점을 찾으면 코드를 커밋해서 CI/CD 를 통해 배포하거나
- 시스템 설정을 변경하고 변경사항을 배포한다.
MTTR을 줄이는 것은 개발자의 경험도 중요하지만, 시스템적으로 최대한 다양한 관점의 정보를 제공할 수 있도록 적절한 정보를 쌓아두고 확인할 수 있게 하는 것이 더 중요하다.
트레이싱 - 메트릭 - 로그
해당 내용은 위에 설명했으니 넘어가자.
다만 로깅을 할 땐, 메트릭을 쌓을때 RED, USE, CASE 같은 방법론(?) 들을 참조해서 적절히 쌓고 확인하는 것을 추천한다.