쉽게 설명한 클린 / 헥사고날 아키텍쳐
2022년 02월 13일 작성TL;DR
Ports: 인터페이스, DI(Dependency Inversion) 를 위한 추상화
Adapters: 포트를 통해 인프라와 실제로 연결하는 부분만 담당하는 구현체
Domain Model: 실제 핵심 비즈니스 로직을 처리하는 부분
Domain Service(클린 아키텍쳐에서의 UseCase): 도메인 모델과 어댑터를 이용해서 비즈니스 로직과 인프라를 오케스트레이션 하는 dumb한 레이어
도메인 모델이 빈약(amnemic) 하다면, 그냥 레이어드 아키텍쳐에 SOLID 를 잘 지켜서 개발하기만 해도 충분하다.
시작하며
너무 빨리 적응하려고 나댔던 탓인지, 입사 둘째주부터 바로 서비스 개발을 시작하게 되었다.
이제는 프로토타이핑이 아니라 프로덕션용 코드(생명주기가 길 것으로 예상되는 코드)를 작성하다보니 기존의 코드스타일로는 테스트 작성과 유지보수가 쉽지 않을 것이 눈에 선했다.
그래서 예전부터 공부만 해두고 써먹지 못했던 헥사고날(a.k.a 포트앤어댑터 / 어니언) 아키텍쳐를 적용해보기로 했다. (개인적으로는 포트앤어댑터로 부르는 것을 더 좋아한다.)
약 4주 동안 다양한 아티클과 영상을 보고, 코드를 쉴새 두드리고 다듬은 뒤에 제대로 된 서비스가 만들어졌고, 그 결과 헥사고날에 대해 가벼운 토론을 할 수 있을 정도로는 이해할 수 있게 되었다.
본 글에서는 헥사고날 아키텍쳐에 대한 설명과 각 컴포넌트들, 그리고 특별히 웹서비스 구현시에 고려할만한 내용을 정리해본다.
헥사고날 아키텍쳐가 무엇인가?
어떤 과정을 거쳐서 지금의 클린/헥사고날 아키텍쳐가 나오게 되었는지 이 글1 에서 상당히 잘 설명해주고 있다.
다만, 해당 글은 헥사고날 아키텍쳐와 클린 아키텍쳐를 섞어서 설명하기 때문에 그림이나 전체적인 개념이 좀 뒤섞여 있어서 둘의 차이를 알고자 하는 목적으로 보면 헷갈리는 부분이 있다. 그래도 두 아키텍쳐 모두 근본적으로 해결하고 싶은 문제는 동일하기 때문에 대략의 개념을 잡는 시작점으로는 문제가 없는 것 같다.
클린/헥사고날 아키텍쳐를 요약하면 비즈니스 로직(도메인 모델)을 인프라(외부세계)에서 분리한다 는 것이다.
위의 그림에서 보듯이 엔티티(또는 도메인 모델) 가 가장 안에 있고, 엔티티에 접근하기 위해서는 밖의 레이어들을 거쳐서 들어올 수 밖에 없다.
의존성은 반드시 밖에서 안으로만 존재하며 안쪽에 있는 레이어는 밖의 레이어에 대해서 알면 안된다. 안다 또는 의존한다 는 개념은 코드상에서 참조한다 또는 임포팅 한다고 생각하면 편하다.
따라서 분리라는것은 안쪽에 있는 레이어가 밖의 레이어에 대해서 알지 못하도록 한다 라는 의미이다.
클린 아키텍쳐와 헥사고날 아키텍쳐는 위의 분리를 구현하는 방식의 차이가 있을 뿐, 동작하는 코드를 보면 데이터는 사실 비슷한 형태로 흐른다.
클린 아키텍쳐의 동작과정은 이 영상2 을 보면 쉽게 이해할 수 있다.
개인적으로는 클린 아키텍쳐보다 헥사고날 아키텍쳐를 더 좋아하는데, 다른 이름인 포트와 어댑터라는 이름과 동작이 더 직관적이며, 조금이나마 더 단순한 형태라 람다와 잘 맞기 때문이다.
레이어드 아키텍쳐와의 차이
위의 내용만 읽어보면 기존에 잘 사용하고 있던 레이어드 아키텍쳐와 큰 차이가 안느껴지는 것 같다.
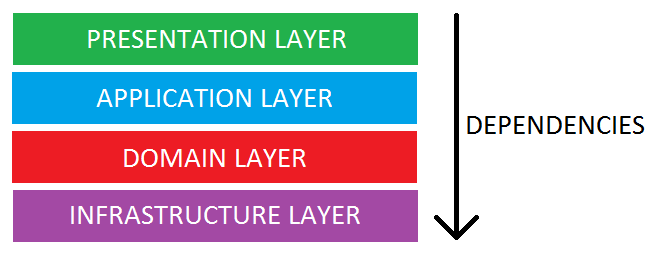
레이어드 아키텍쳐도 비즈니스 로직 레이어를 외부와 분리하기 위해서 나온 아키텍쳐이기 때문일 것이다.
실제로 SOLID를 잘 적용한 레이어드 아키텍쳐는 클린아키텍쳐의 장점을 상당 부분 누릴 수 있다고 생각한다.
하지만 이 글3에 설명되어 있듯이, UseCase 또는 Ports 라는 추상화를 도입해서 의존성을 역전하는 것이 레이어드와 두 아키텍쳐의 가장 큰 차이점이라고 볼 수 있다.
그리고 추상화 계층을 도입하면 의존성을 줄이거나 역전할 수 있지만 대부분 복잡도가 올라간다. 따라서 복잡도가 많이 필요하지 않은 작은 시스템에서는 레이어드에 비해 얻을 수 있는 장점이 크지 않을 수 있다.
여튼, 이렇게 복잡도를 올리면서까지 외부에 대한 의존성을 완전히 제거한 것이 엔티티 또는 도메인 모델 이며, 클린 아키텍쳐와 레이어드 아키텍쳐의 가장 큰 차이점은 이 도메인 모델의 유무라고도 볼 수 있다.
레이어드 아키텍쳐에서 모든 비즈니스 로직은 서비스레이어에 있지만, 클린 아키텍쳐에서는 도메인 모델에 모든 비즈니스 로직이 있고, 나머지 부분에서는 도메인 모델을 위한 통신/오케스트레이션을 담당한다.
Vertical Slice Architecture
번외로 버티컬 슬라이스 아키텍쳐를 간단히 살펴보자.
사실 아키텍쳐라기보다는 프로젝트 레이아웃이라고 볼 수도 있다.
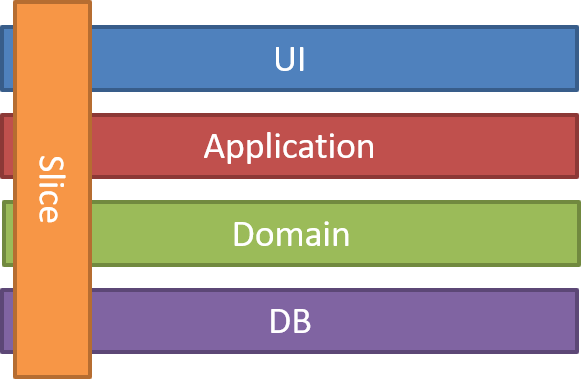
레이어드 아키텍쳐는 보통 엔티티 또는 데이터베이스 스키마 기준으로 구성되는 경우가 많다. 전체 구성이 이렇게 되어 있기 때문에, 당연히 비즈니스로직도 데이터베이스 스키마 기준으로 구성되고 각 서비스가 서로를 참조하게 된다. (도메인 경계가 서비스 경계와 일치하지 않기 때문)
하지만 도메인 모델은 기존의 데이터 중심의 비즈니스 로직 구성 대신, 사용자의 유즈케이스를 중심으로 비즈니스 로직이 구성되며, 각 유즈케이스를 담당하는 도메인 모델은 서로를 참조하지 않는다.
따라서 비즈니스 로직이 레이어 아키텍쳐의 전체 레이어 관통하는 유즈케이스의 집합으로 구성된다.
이 생각을 좀 더 발전시킨 것이 위의 그림인 Vertical Sliced Architecture 인데, 각 유즈케이스를 담당하는 모든 레이어를 하나로 묶어서 (또는 한 폴더에 모아서) 프로젝트를 구성한다.
이렇게 함으로써 개발할때 한 기능에 대한 모든 코드가 한 곳에 몰려있게 되고(폴더레벨의 cohesion 이 올라간다.), 코딩시 파일간 점프하는 뎁스가 줄어들게 된다.
헥사고날 아키텍쳐를 구성하는 요소
위에서 너무 클린 아키텍쳐 중심으로 설명했는데, 이 영상4은 좀 더 헥사고날에 집중해서 잘 설명하고 있다.

헥사고날 아키텍쳐에 대한 다른 글들에서는 여러가지 새로운 컴포넌트나 개념을 추가해 구현하는 경우가 많다. 자신만의 개념으로 발전시키는 것은 매우 좋은 현상이지만, 처음 배우는 사람들에게는 오히려 헷갈리는 경우가 많다.
그리고 초기에 제안된 컴포넌트들만으로도 프로젝트를 충분히 구현할 수 있으며, 여기서도 기본 컴포넌트들만 소개하려고 한다.
데이터 흐름
사용자 요청의 처리흐름을 대략 소개하면, 사용자의 요청은 왼쪽에서 들어와서 오른쪽으로 처리되며,
좌측의 Adapters를 통해 사용자의 요청을 받아서Applicaiton Service에 전달한다. 이 때 서비스와 어댑터는Ports를 인터페이스로 사용해서 통신한다. (어댑터 디자인패턴 같은 느낌)Application Service는 들어온 요청을Domain Model로 전달한다.Domain Model은 전달받은 요청으로 비즈니스 요청을 처리하고우측에 있는 Adapters를 통해 외부의 데이터를 가져오거나 처리된 데이터를 외부로 저장한다.- 필요하다면
Application Service는 도메인 모델의 처리결과를 전달받아 다시 사용자에게 반환해준다.
위에 소개했던 링크들만 읽어도 흐름은 이해가 잘 될거라고 생각한다.
하지만 막상 구현을 하려면 무슨 컴포넌트를 어떤 식으로 만들고 사용해야 하는지가 막막하다.
아래에서 각 컴포넌트들에 대한 좀 더 상세한 설명과, 구현시에 고려할 각 컴포넌트들의 역할을 좀 더 명확히 살펴보자
Adapters
앞에서 본 그림에서 어댑터는 2가지 종류가 있는데, 왼쪽에 사용자의 요청을 받아들일때 사용되는 어댑터를 primary adapter 라고 부르고, 우측에 있는 도메인 모델의 처리에 사용되는 어댑터를 secondary adapter 라고 부른다.
Primary Adapter
실제로 구현하는 경우 이벤트 드리븐 서비스로 구성될 경우에는 primary adapter 의 역할이 명확하지만, 웹 서비스의 경우에는 약간 모호해지는 것 같다.
따라서 primary adapter 는 웹 프레임워크들의 controller 또는 람다의 handler 와 같은 개념에 통합되어 사용되며 아래에 소개할 어플리케이션 서비스를 인스턴스화 하여 비즈니스 로직을 실행하고 결과를 사용자에게 반환해준다.
아래 코드는 MSK 토픽의 다운스트림으로 설정한 람다 핸들러 코드이다.
import TaskRepository from '../adapters/dynamodb-task-repository';
import JobRepository from '../adapters/dynamodb-job-repository';
var taskService: TaskService;
var coldStart: boolean = true;
function bootstrap() {
if (coldStart) {
const tableName = process.env.TABLE_NAME!;
assert.ok(tableName, 'env TABLE_NAME is required');
const gs1IndexName = process.env.GS1_INDEX_NAME!;
assert.ok(gs1IndexName, 'env GS1_INDEX_NAME is required');
const dynamodb = new AWS.DynamoDB.DocumentClient({ service: new AWS.DynamoDB() });
taskService = new TaskService(
new TaskRepository(dynamodb, tableName),
new JobRepository(dynamodb, tableName, gs1IndexName),
);
coldStart = false;
}
}
export const handler = async (event: MSKEvent, context: Context): Promise<void> => {
console.debug(JSON.stringify(event));
bootstrap();
const records = filterRecords(event);
const commands = records.map<CreateTaskCommand>(decodeRecord);
const tasks = commands.map(command => command.task).filter(Boolean);
const results = await taskService.createTasksAndJobs(tasks);
return;
}
);
실제 만들어지는 객체들의 의미보다 primary adapter 로서의 handler 역할, 데이터의 흐름에 집중하자.
primary adapter 는 먼저 클라이언트로 부터 입력받은 값의 유효성을 체크하고 적절한 형태로 가공한다.
TaskRepository, JobRepository 라는 dynamodb 어댑터들을 가져와서 어플리케이션 서비스인 TaskService 를 생성하고 호출한다.
TaskService 는 도메인 모델을 통해 비즈니스 로직을 실행하여, 태스크와 잡들을 생성해준다.
Secondary Adapter
생성된 어플리케이션 서비스는 내부에서 도메인모델을 호출하게 된다.
도메인 모델도 외부와의 통신이 필요한 작업이 있을 수 있다.
이 경우 도메인 모델은 포트를 통해 우측에 있는 어댑터를 호출 할 수 있다.
아래는 다이나모디비와 통신할때 사용하는 어댑터이다.
import { Task } from '../interfaces/task';
import { TaskRepository } from '../ports/task';
class DynamoDBAdapter implements TaskRepository {
constructor(
readonly client: AWS.DynamoDB.DocumentClient,
readonly tableName: string,
) { }
async save(task: ITask): Promise<boolean> {
if (await this.isExists(task.id)) {
return false;
}
await this.client.put({
TableName: this.tableName,
Item: {
PK: TaskSchema.Task.PK(task.id),
SK: TaskSchema.Task.SK(task.id),
...task,
},
ConditionExpression: 'attribute_not_exists(PK) AND attribute_not_exists(SK)',
}).promise();
return true;
}
async listTasks(): Promise<ITask[]> {
const items = await this.client.query({
TableName: this.tableName
Key: {
PK: 'TASK#RECENT',
},
});
return items.Item ? items.Item as ITask[] : [];
}
}
secondary adapter 는 외부와의 통신에 대한 구현만 담당한다. (primary adapter 도 마찬가지)
두 어댑터의 가장 큰 특징은, DIP(Dependency Inversion Principal) 를 기반으로 하고 있다는 점이다.
primary adapter 는 서비스에 주입(injection) 되어 서비스에 의해 호출되고,
// Inside Primary Adapter
taskService = new TaskService(
new TaskRepository(dynamodb, tableName),
new JobRepository(dynamodb, tableName, gs1IndexName)
);
secondary adapter 는 도메인 모델에 주입되어 도메인 모델에 의해 호출된다.
// Inside Domain Model
async save(repo: TaskRepository): Promise<void> {
await repo.save({
id: this.id,
name: this.name,
topic: this.topic,
startAt: this.startAt,
meta: this.meta,
description: this.description,
});
}
그리고 두 어댑터 모두 비즈니스 로직은 전혀 들어가지 않는다.
Ports
포트는 단순히 인터페이스이다. 어댑터는 이 포트를 implements 하여 실제 동작을 구현하게 된다.
import { ITask } from '../interfaces/task';
export interface TaskRepository {
save(task: ITask): Promise<boolean>;
listTasks(): Promise<ITask[]>;
}
파이썬3을 쓰는 경우 ABC 보다 Protocol 을 쓰는 것이 좀 더 유연하게 작업할 수 있다. (장단점이 있지만)
Applcation Service / UseCase
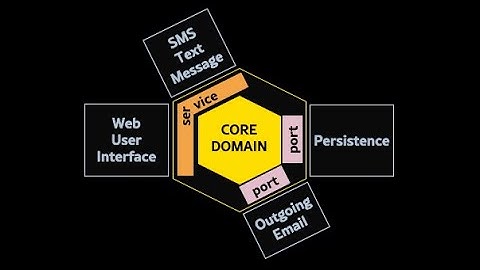
사용자 요청이 왼쪽에서 오른쪽으로만 들어온다는 것을 확실히 인지하고 있다면, 2중 헥사곤의 첫 그림도 명확하게 다가올 것이다.
하지만 처음 헥사고날을 접하는 사람에게는 위의 그림이 조금 더 어플리케이션 서비스를 명확히 보여주는 것 같기도 하다.
위의 그림대로 primary adapter 를 통해 어플리케이션 서비스를 생성(instantiation) 해주고 해당 서비스가 클라이언트에 대한 반환을 책임진다.
위의 그림에서 어플리케이션 서비스에서만 도메인 모델과 포트에 모두 대한 의존성이 있다. 의존성은 import 가 가능하다고 해석해도 틀리지 않다.
따라서 어플리케이션 서비스는 어댑터들과 도메인모델의 오케스트레이션을 담당하게 된다. (도메인 이벤트를 이벤트 버스로 보내준다거나 하는 작업도 여기서 한다.)
도메인 객체는 어디서 만들지?
import { ITask } from '../interfaces/task';
import { Task } from '../domain/task';
import { TaskRepository } from '../ports/task';
import { JobRepository } from '../ports/job';
class TaskService {
constructor(
private readonly taskRepo: TaskRepository,
private readonly jobRepo: JobRepository
) {}
toTask(task: ITask) {
return new Task({ ...task });
}
async createJobsForTasks() {
const dtoTasks = await taskRepo.listTasks();
const tasks = dtoTasks.map(toTask);
await Promise.all(tasks.map((task) => task.schedulNextJob()));
}
}
export default TaskService;
DDD 에서 레포지토리는 도메인 객체를 직접 외부에서 가져오고 저장하는 것이 자연스럽다. 그래서 많은 DDD 예제들에서도 레포지토리는 예외적으로 도메인객체를 바로 리턴한다.
그래서 DDD 를 좀 아는 사람은 서비스에서 도메인 객체를 만드는 toTask 부분이 이상하다고 볼 수도 있는데, 사실 이는 선택의 문제이다.
약간 더 설명을 추가하면,
먼저 어댑터인 레포지토리는 외부에서 DTO 를 이용해서 저장된 데이터를 가져온다. 그리고 DTO 를 도메인 모델에서 쓰기 위해서는 도메인 객체로 변환해야한다. 이 때 DTO 와 도메인 객체간의 변환을 어디서 해주느냐가 위에서 말한 선택의 문제이다.
즉, 레포지토리가 반환하는 값이 DTO 라면, 서비스에서 DTO 를 도메인 객체로 변환해줘야한다. 혹은 레포지토리가 반환하는 값이 도메인 객체라면, 레포지토리에서 도메인 객체를 알고(임포트) 변환해서 반환해줘야한다.
하지만 원래 헥사고날 그림상 어댑터가 도메인 객체를 알고있는 것은 원래 의도와 어긋난다.
따라서 개인적으로는 DTO 에서 도메인 객체로의 변환은 서비스에서 담당하고, 도메인 객체는 도메인 모델에서만 쓰도록 하는 편이 좋다고 생각한다
Domain Model / Entities
도메인 모델은 모든 비즈니스 로직이 포함된다.
도메인 모델에서 다루는 엔티티를 도메인 객체라고 부르며, 이 도메인 객체은 서비스를 벗어나서는 안된다. 서비스를 벗어나야 하는 경우 반드시 사전에 DTO(Data Transfer Object)로 변경되어야 한다.
아래는 예제를 위해 간단한 작업만 있지만, 실제로 엔티티에 변경이 일어나야 하는 모든 작업이 여기에 구현되어 있어야 한다.
// domain/model.ts
import { JobRepository } from '../ports/job';
import { TaskRepository } from '../ports/task';
export interface TaskProps {
readonly id: string;
readonly name: string;
readonly topic: string;
readonly startAt: string;
readonly meta: { [key: string]: string };
readonly description?: string;
readonly updatedAt?: string;
}
export class Task {
readonly id: string;
readonly name: string;
readonly topic: string;
readonly startAt: string;
readonly description?: string;
constructor(props: TaskProps) {
this.id = props.id;
this.name = props.name;
this.topic = props.topic;
(this.startAt = props.startAt), (this.description = props.description);
}
async save(repo: TaskRepository): Promise<void> {
await repo.save({
id: this.id,
name: this.name,
topic: this.topic,
startAt: this.startAt,
description: this.description,
});
}
async scheduleJob(repo: JobRepository): Promise<void> {
await repo.save({
id: this.id,
taskId: this.id,
taskName: this.name,
topic: this.topic,
startAt: this.startAt,
status: JobStatus.Initialized,
});
}
}
왜 헥사고날 아키텍쳐를 쓰는가?
관심사의 분리
각 컴포넌트의 역할이 명확해지기 때문에 봐야하는 포인트를 고민하지 않아도 되고, 새로운 개발자가 들어오더라도 쉽게 봐야할 곳을 찾을 수 있다.
외부와의 연결에 문제가 생기면? 어댑터를 보면 된다.
인터페이스는? 포트를 보면 된다.
처리중간에 EventBridge 에 이벤트를 보내고 싶다면? 서비스를 보면 된다.
비즈니스 로직이 제대로 동작하지 않으면? 도메인 모델을 보면 된다.
좀 더 쉬운 테스트
각 컴포넌트의 역할만큼이나 의존성이 명확히기 때문에 테스트의 범위도 명확해진다.
- primary adapter 는 서비스의 내부 구현을 mocking 할 필요 없이, 외부에서 들어온 데이터가 잘 가공되어 서비스에 전달되는지만 확인한다.
- 서비스는 각 어댑터나 도메인 객체가 정상적으로 동작하는지 확인할 필요 없이, 순서대로 오케스트레이션 잘 되는지만 확인한다. 이 때 모든 어댑터는 포트를 기반으로 하기 때문에, 쉽게 FakeAdapter 를 작성하여 서비스를 테스트 해볼 수 있다.
- secondary 어댑터는 다이나모디비나 카프카, 레디스 등의 본인이 담당하는 외부서비스를 mocking 해서 파라미터값이 의도대로 전달되는지를 확인한다.
- 도메인 로직은 모든 비즈니스 로직에 대한 테스트를 작성하게 되지만 의존성이 없기 때문에 mocking 할 필요가 거의 없다. (있더라도 포트를 통해 secondary adapter 를 쉽게 모킹할 수 있다.)
- 마지막으로 위의 모든 과정에서 포트는 검증이 되기 때문에 포트는 따로 테스트할 필요가 없다.
아래는 어플리케이션 서비스에 대한 테스트 일부이다. ports 를 이용해서 가짜 어댑터를 쉽게 생성하고 테스트해볼 수 있다.
import TaskService from '../../services/task';
import { TaskRepository } from '../../ports/task';
import { JobRepository } from '../../ports/job';
import { Task as ITask } from '../../interfaces/task';
import { Task } from '../../domain/task';
class FakeTaskRepository implements TaskRepository {
save = jest.fn();
delete = jest.fn();
}
class FakeJobRepository implements JobRepository {
save = jest.fn();
delete = jest.fn();
updateStatus = jest.fn();
listStartableJobs = jest.fn();
}
describe('create task and job', () => {
it('success', async () => {
const taskRepo = new FakeTaskRepository();
const jobRepo = new FakeJobRepository();
const taskService = new TaskService(taskRepo, jobRepo);
const dtoTask: ITask = {
id: 'test-task-1',
name: 'test-task-1',
topic: 'test-topic-1',
startAt: DateTime.now().toISO(),
};
const task = taskService.toTask(dtoTask);
await taskService.createTaskAndJob(task);
expect(taskRepo.save).toBeCalledTimes(1);
expect(jobRepo.save).toBeCalledTimes(1);
});
});
일반적으로 테스트 피라미드5 가 잘 지켜질수록 좋은 테스트 / 서비스코드이다.
실제로 도메인 모델을 잘 작성했을수록 서비스와 도메인 로직의 유닛테스트가 가장 많은 테스트를 가지게 되고,
통합테스트 부분인 secondary 어댑터들이 좀더 적은 테스트, 그리고 primary adapter 가 가장 적은 테스트를 가지게 된다.
마치며
헥사고날의 예제 코드는 여기6. 본 글의 예제는 완전히 서버리스로 작업된 코드라 로컬에서 테스트가 불가능하여 새로 작성했다. (대신 메이저한 타입스크립트 대신 약간 마이너한 golang 을 사용했다.)
해당 코드는 saga 패턴을 transational outbox7 패턴으로 구현한다. 특정 목적을 가지고 만든 예제코드라 헥사고날만 공부하기에는 어려울 수 있지만 도커만 있으면 일단 로컬에서 돌려볼 수 있게 되어 있다. 사용한 패턴들도 시간나면 블로그에 써야겠다.
여튼 모든 서비스가 마이크로 서비스 일 필요가 없듯이,
내 도메인 모델이 빈약하거나, 아예 DDD 를 하지 않는 상황이라면 굳이 클린아키텍쳐 스타일을 쓸 필요가 없다.
이럴거면 그냥 레이어드 아키텍쳐 쓰는거보다 크게 나은것도 없는데 왜 이짓을 하고 있지? 라는 생각을 하게 되기 때문이고, 이런 경우 실제로 레이어 아키텍쳐가 더 나을 수도 있다.
비즈니스 목적에 맞는 툴이 최고의 툴이라는 사실을 잊지 말자.
람다에 좀 더 가볍게 적용할 수 있는 형태로 이 글8을 참고하자. 클래스 없이 함수만으로 구현한 포트앤어댑터 람다 예제.