개발자로서 LLM 사용을 위해 알아두면 좋은 내용들
2023년 05월 02일 작성TL;DR
코드는 여기1.
notebook 폴더 아래에 있는 노트북들을 세이지메이커 gpu 인스턴스에서 실행하면 된다.
시작하며
최근 몇 주동안 LLM (Large language model) 모델로 프로토타이핑을 진행하게 되었는데, 그 몇 주동안 너무 많은 모델들이 쏟아져나와서 굉장히 고생을 한 것 같다.
대략 사용자 입장에서 공부하면서 어려웠던 점은 아래와 같았다.
- 너무 다양한 모델들이 나오고 있는데 추구하는 바가 조금씩 다르다는 점
- 파인튜닝 기법이 다양하게 있고 다행히도 (Q)LoRA 라는 기법으로 통합되고 있지만, 또 새로운 기법이 나오고 있다는 점(IA3 등)
- 모델을 배포하고나서 텍스트 생성을 해야하는데 이 때도 다양한 파라미터들과 기술들이 있다는 점 (xformer 등)
본 글에서는, 서버 개발자 입장에서 빠르게 LLM 전반에 대한 공부를 훑어봐야할 경우 도움이 될만한 내용을 압축해서 정리해본다.
배경지식
트랜스포머
일단 시작은 트랜스포머를 대충 알아야한다. 트랜스포머에 대한 좀 더 디테일하고 쉬운 설명은 여기2를 참고하자.
여튼 트랜스포머는 인코더와 디코더로 구성되어 있고, 어텐션을 통해 각 레이어간 정보를 유실하지 않고 잘 전달할 수 있다.
뒤에 나오는 PEFT 라고 불리는 파인튜닝 기법들은 이 어텐션 기법과 연관되어 있는데, 어텐션은 트랜스포머의 핵심 아이디어중 하나이기 때문이다.
어텐션은 쿼리, 키, 밸류로 구성되며, 이를 이용해 각 위치의 중요도를 결정하는데 도움을 준다는 점 정도만 기억해두자.
어텐션의 의미를 짧게 설명하면, 쿼리, 키, 밸류는 모두 벡터인데, 여기서 키/밸류는 파이썬의 dictionary 역할적으로 비슷하다. 어텐션이 하고 싶은 것은 키/밸류 벡터를 학습해두고 있다가 어떤 쿼리가 들어오면 해당 쿼리에 맞는 키를 찾아서 밸류를 반환하는 것이다.
GPT
GPT 는 트랜스포머에서 디코더 부분만 사용하여 만든 언어모델이다.
현재 GPT2, GPT3, GPT3.5-turbo, GPT-4 모델이 나와있다.
GPT2 나 3나 3.5는 모델의 크기의 차이만 있다고 봐도 무방하며, 상세한 내용은 여기3를 참고하자.
GPT2 는 파라미터수가 백만(M) 단위이지만 GPT3 부터는 십억(B) 단위로 올라가며, GPT3 는 175B 의 파라미터를 가지고 있다.
GPT-4 는 공개된 내용이 많이 없지만, GPT3.5 보다 모델이 더 크며, 멀티모달 쿼리를 지원하는 모델로 알려져있다.
ChatGPT
LLM 의 민주화에 대한 시작은 ChatGPT 라고 볼 수 있다.
ChatGPT 는 GPT3.5-turbo 를 기반으로 턴바이턴 생성을 할 수 있는 LLM 플랫폼 이며, GPT3.5 는 GPT3 에 인스트럭션 파인튜닝 기법(구글에서 FLAN 이라는 이름으로 처음 소개한)과 RLHF (Reinforcement Learning with Human Feedback) 라는 학습 방법을 적용하여, 사람이 좀 더 선호할만한 답변을 생성하도록 학습시킨 모델이다.
ChatGPT 가 학습되고 동작하는 방식은 아래에서 잘 설명하고 있다.
ChatGPT 덕분에 한때 RLHF 가 각광받았었지만 최근에는 PPO 방식의 복잡성 때문에, RLHF 대신 리워드 모델 없이 사용자의 선호도를 직접 학습시키는 (DPO - Direct Preference Optimization) 방식이 많이 선호되는 것 같다.
최신 모델들
아래 영상에서 최신 모델의 흐름을 대략적으로 확인할 수 있다.
개인적으로 최신 모델은 크게 2갈래로 나뉘고 있는 것 같은데, GPT-J 기반의 모델들과 라마 (Llama) 기반의 모델들이다.
둘다 디코더 기반의 모델이며, seq2seq 인 T5 등 다른 모델들은 위의 두 모델에 비해 생성 측면에서는 성능이 떨어진다. (원래 seq2seq 모델이 번역과 요약에 뛰어난 편으로 알려져있으니..)
2023년 3월에 메타에서 라마 모델4을 공개하고나서 이를 기반으로 다양한 모델들이 나오기 시작했다.
가장 많이 알려진 스탠포드 대학에서 만든 Alpaca 도 라마를 기반으로 Instruction Learning (self-instruct) 기법을 적용한 모델이고, ChatGPT 와 성능평가에서 90% 대의 성능을 보여줬다던 Vicuna 도 라마 기반이다.
라마 모델은 3B 부터 65B 까지 크기가 다양하게 공개되어 있으며, KoAlpaca 같이 한국어를 데이터를 보강한 모델들도 있다.(최신 KoAlpaca 는 백본을 라마 모델이 아니라 polyglot 을 쓰는거 같고, 해당 모델은 이름대로 여러 언어를 지원하지만 한글을 제외하면 모델의 성능 자체는 라마보다 많이 떨어지는 것 같다.)
라마 기반으로 가장 각광받는 모델들은 Alpaca5, Vicuna6, StableLM/StableVicuna, WizardLM 이 있다.
GPT-J 는 6.7B 정도의 상대적으로 크지 않은 모델이지만, 파인튜닝을 적절히 해주면 일부 작업에서는 175B 의 GPT3 보다 성능이 잘 나온다고 알려져 있다.
GPT-J 기반으로 최근 각광받는 모델들은 GPT4ALL-J7, Dolly8, MPT, Falcon 이 있다.
특히 Falcon 은 QLoRA 와 합쳐져서 40B 모델을 30GB 급의 단일 GPU 에서 파인튜닝할 수 있어서 인기를 끌고 있다.
최근 이러한 오픈소스 모델들이 인기있는 이유는, 모델 크기가 작더라도 좋은 데이터를(특히 인스트럭션) 충분히 학습시키면 더 큰 모델보다 성능이 좋아진다는 것이 검증되고 있고, 그 성능이 175B짜리 GPT3 와도 비벼볼만 하다는 데 있는 것 같다.
라이센스
라마 모델은 CC-BY-NC 라이센스를 사용하므로 라마를 기반으로 파생된 모든 모델은(정확히는 라마 파라미터를 쓰는 모델) 상업용으로 사용할 수 없다.
LightiningAI 에서 만든 Lit-Llama 같은 게 있지만, 코드에 대해서만 라이센스를 우회했지 모델의 파라미터는 그대로 GPL을 따르게 된다. 직접 처음부터 학습하지 않으면 상업적으로 쓸 수 없기는 매한가지다. (최근 OpenLlama 라는 모델이 나왔고 이 모델은 상업적으로 사용이 가능하다.)
대부분의 모델들은 추가 학습데이터를 만들때(특히 인스트럭션) ChatGPT 를 사용했기 때문에 역시나 라이센스에서 완전히 자유롭지 못하다.
반면, Falcon, MPT, Dolly 같은 모델들은 아파치2.0 라이센스를 따르므로 상업적으로도 자유롭게 사용할 수 있다.
모델 크기
라마가 유출된 덕분에 GPU 카드를 가지고 있는 개인 개발자들이 다양한 컨트리뷰션을 하고 있으며, 이 때문에 모델의 크기를 하나의 GPU 에 넣는 시도도 많아 지고 있다.
일반적으로 7B 크기를 가진 모델들은 float16(2바이트) 을 사용할 때, 14GB 정도의 GPU 메모리를 사용한다. (실제로는 6.7B 정도 인데 반올림해서 7B 라고 부른다. 따라서 모델 크기가 두배인데 아니라 14B 가 아니라 13B 가 된다.)
하지만 상용으로 팔린 모델들의 GPU 메모리 크기가 보통 8~12GB 이므로 단순 float16 으로는 개인 컴퓨터에 모델을 올리기 어렵다. 따라서 다소 속도를 희생하더라도 이 안에 모델을 구겨넣는 방법들이 많이 나오고 있다.
대표적으로 4bit/8bit quantization 이 있고, 목적이 약간 다르지만 cpu offload(컴퓨팅 할때만 GPU 메모리에 올리는 방식) 방식도 있다.
quantization 은 float32 의 공간을 4/8bit int 공간으로 사상해서 메모리에 로드 함으로써 메모리를 절약하는 방식인데, 대신 모델 추론 시에는 다시 float32 으로 변환해서 사용하므로 추론 속도가 느려진다는 단점이 있다. (이 때문에 프로덕션화 하기에는 속도가 느리다.)
참고로 AWS 의 G4DN 이나 P3 인스턴스들은 16GB GPU 메모리를 가지고 있는데, float16 으로 7B 모델을 실행하더라도 동시에 여러개의 추론을 실행하면 메모리 문제 때문에 긴 문장 추론이 여러울 수 있다.
다행히 G5 인스턴스들은 24GB 를 제공하지만, 해당 인스턴스 타입은 아직 한국에 지원이 안되며, Colab Pro(유료) 가 제공하는 32GB 에 비해 약간 아쉽다.
여튼, 7B 모델보다 큰 모델을 프로덕션에서 서비스하려면 속도를 다소 희생하고 quantization 을 사용하거나, 하나의 모델을 여러 GPU 에 분산해서 올리고 generation 하는 방식을 써야한다.
데이터
요새 모델들은 대부분 the Pile 데이터를 기반으로, 다양한 데이터를 추가하여 학습을 한다.
대부분의 추가 데이터들은 인스트럭션 데이터들이며, 사람이 직접 만들어내거나 LLM(ChatGPT 등) 을 이용해서 자동으로 만들어 낸다.
대표적으로 Alpaca, Dolly 15k, Evo-instruct 가 잘 알려져 있으며, 그 외에도 다양한 곳에서 다양한 인스트럭션 데이터셋을 만들어내고 있다.
또한 복잡한 인스트럭션을 만들어서 학습하면 더 성능이 올라간다는 사실이 알려지면서 (복잡한 프롬프트를 더 잘 처리한다), LLM 을 이용하여 인스트럭션을 스스로 복잡하게 만들고 학습하는 방법들도 연구되고 있다.(WizardLM)
파인튜닝, PEFT
알파카가 7B 라마 모델에 52k 개의 데이터를 3 epoch 만큼 파인튜닝 하는데 A100 8 GPU 로 3시간 걸렸다고 한다. (AWS 로 치면 p3.24xlarge 정도인데, 비용은 대략 100불정도 들었다.)
GPU 개수만큼 GPU 메모리도 중요한데, 7B 학습시 최소 70GB+ 의 메모리가 필요하므로 (bfloat16 기준) 메모리 때문에 강제로 높은 사양의 GPU 인스턴스를 써야하기도 한다.
여튼, 학계에서는 다양한 가설 검증을 위해서 모델을 자주 학습해야하는데, 비용과 시간의 압박이 심한 상태이다. 이를 극복하고자 비용효율적으로 학습하는 여러 방법들이 나왔고, 이런 방법들을 PEFT (Parameter Efficient Fine Tuning) 이라고 부른다.
현재 잘 알려진 PEFT 방식은 adapter tuning, prefix tuning, prompt tuning, LoRA, IA3 가 있으며, 각 방식의 공통점은 백본 모델의 파라미터를 건드리지 않으며 상대적으로 작은 추가 파라미터만 학습하는 방식이라는 점이다.
LoRA (Low-rank Adaptation)
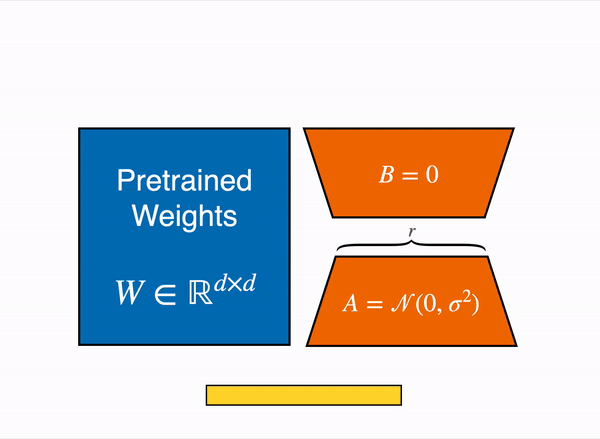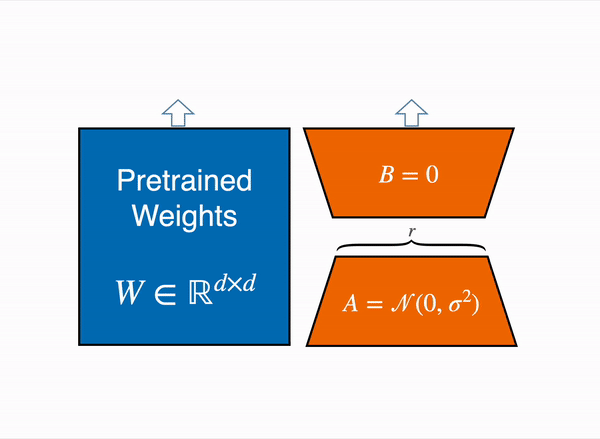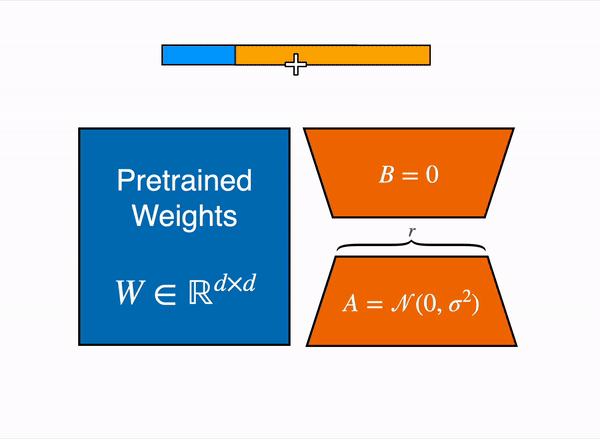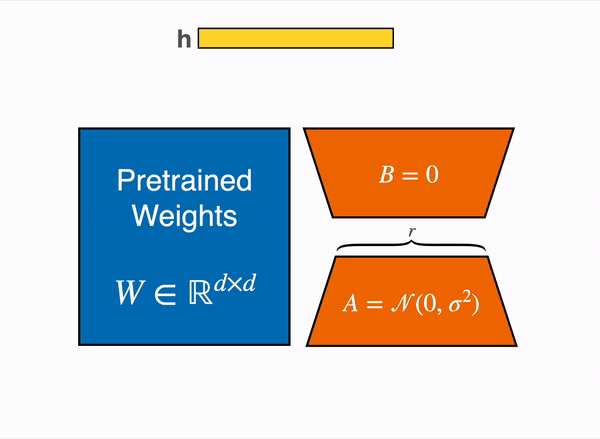
그리고 이중에 현재 가장 많이 쓰이는 방식은 low-rank adaptation 또는 LoRA9 라고 불리는 방식이다.
어느 트랜스포머에서나 적용할 수 있기 때문에, 스테이블디퓨전에서도 이미 많이 쓰이고 있다.
대충 LoRA 보다 앞서 나온 방법들은 추론시 속도에 영향을 주거나(adapter), 학습시 모델의 제약을 걸게 되는데(prefix) LoRA 는 그런 단점을 다 우회하고 적은 파라미터로 빠르게 학습할 수 있다는 장점이 있다.
LoRA 의 아이디어는 대충 이렇다.
GPT3 175B 모델이 상대적으로 작은 모델들에게 성능이 비벼지는 이유는, 실제로 파라미터의 랭크가 낮기 때문이 아닐까? 하는 가설을 세우게 된다. (인간은 뇌를 죽을때 까지 20% 정도 쓴다는 가설같이..)
만약 실제로 파라미터의 랭크가 낮다면, 백프로퍼게이션시 파라미터 업데이트를 위한 델타값도 랭크가 낮을 것이므로, 파라미터 델타값을 더 작지만 계수는 높은 행렬로 근사시켜서 학습하면, 전체 파라미터를 학습하지 않아도 된다는 가설로 이어진다. (매트릭스 Rank 에 대한 내용은 여기10를 참조하자.)
infused adapter by inhibiting and amplifying inner activations or IA3 는 더 최근에 나온 방식으로, 어텐션의 키와 밸류 매트릭스, FF 레이어 를 스케일링 하는 어댑터(?) 를 추가하는 방식이다.
IA3 는 내가 공부를 제대로 안해서 잘 모르겠지만, LoRA 보다 다소 복잡한 대신 LoRA 의 1/10 크기 파라미터로 성능은 더 좋다고 주장하고 있다.(파라미터가 적으니 속도도 더 빠르고… too good to be true?)
RAG (Retrieval Augmented Generation)
LLM 에 요청해서 답변을 받는 것은 closed-book query 라고 볼 수 있다. LLM 은 사전학습을 통해 가지고 있는 정보에 의존하기 때문이다.
그런데 closed-book query 방식에서 최신의 데이터를 요청하면 (예를 들어, 올해 대통령은 누구야?) 최신의 답변을 내놓아야 하는데, closed-book query 방식은 이미 학습된 데이터를 기반으로 답변을 내놓기 때문에 (2021년도 대통령을 답변한다거나) 잘못된 정보를 생성한다.
이렇게 LLM 이 쿼리에 대해 잘못된 정보를 생성하는 현상을 할루시네이션 이라고 한다.
할루시네이션을 해결하는 대표적인 방법으로는 위에 살펴본 파인튜닝 (fine-tuning) 과 RAG 가 있다.
파인튜닝은 모델이 너무 큰 경우 PEFT 를 쓰더라도 학습이 오래 걸리고, 데이터의 추가가 빈번할 경우 파인튜닝 주기를 짧게 해야하기 때문에 잦은 배포에 대한 부담도 동반된다.
또한 LLM 이 모든 쿼리에 대해 새로 학습된 데이터를 꼭 사용한다고 보장 할 수 없다는 점도 문제이다.
![]()
이와 달리, 외부 저장소를 둬서 LLM 이 open-book query 모델로 생성하도록 전환하는 방식이 RAG 이다.
방법은 대략 아래와 같다.
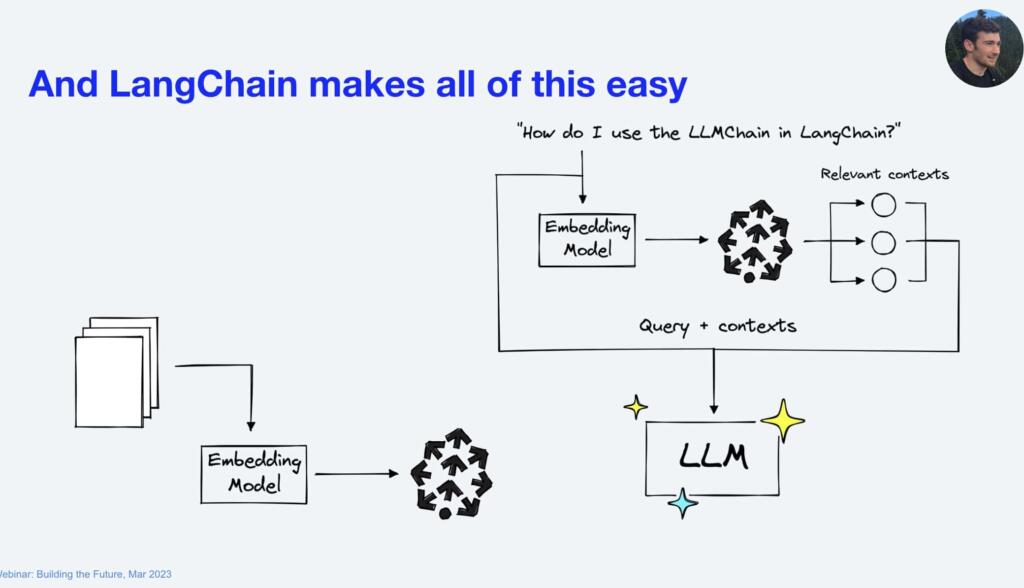
- 필요한 문서들을 모두 임베딩해서 저장해둔다. (보통 OpenAI text-embedding-ada-002, SentenceTransformer 등을 쓴다)
- 사용자가 텍스트 생성 요청을 한다.
- 사용자가 입력한 텍스트를 임베딩하고 해당 임베딩과 유사한 문서 k 개를 가져온다.
- 해당 문서들을 프롬프트에 컨텍스트로 추가해서, 생성에 사용할 프롬프트를 업데이트한다.
- 사용자의 텍스트 생성요청을 진행한다.
Vector database
RAG 에서 임베딩 데이터를 저장해두는 곳을 벡터 데이터 베이스 (vector database) 라고 한다.
해당 서비스의 특성에 대해서 잘 설명한 글11 을 참고하면 직접 구현할 때도 도움이 될 것이다.
여튼 벡터 데이터베이스는 임베딩 데이터를 저장하고 쿼리할 수 있는 저장소인데, 새로운 기술이 아니라 예전에 이미지 검색이나 유사문서 검색을 위해 일밙거으로 사용하던 임베딩 쿼리 방식과 동일하다.
벡터 데이터베이스는 PostgresDB(pgvector), Elasticsearch(or Opensearch) 등을 이용하면 직접 구현할 수도 있지만, 주로 외부 저장소가 필요한 경우에는 Pinecone 을, 로컬 저장소를 쓰는 경우는 ChromaDB, Faiss 등을 많이 쓰고 있다.
Inference
추론 또는 생성은 huggingface 공식문서 두개1213 를 참조하면 된다.
temperature 와 top_p
생성에서 가장 중요한 파라미터는 temperature 와 top_k 또는 top_p 이며, 해당 파라미터를 조절하면서 적절한 값을 찾아야 한다.
원리는 위의 링크에 잘 나와있지만, 대충 temperature 와 top_p 를 올리면 아무말을 잘하게 되고, 낮추면 variation 이 떨어지지만 더 일관된 말을 하게 된다.
그리고 do_sample 파라미터를 줘야 샘플링을 사용하며, 그렇지 않으면 greedy search 를 사용하게 된다.
num_return_sequences
다양한 생성결과를 위해 num_return_sequences 파라미터도 설정할 수 있는데 생성시 토큰 수와 메모리에 영향을 준다. (토큰수에 영향을 주기 때문에 속도에도 영향을 준다고 봐야…)
따라서 메모리를 좀 더 쓰더라도 다양한 생성결과를 원한다면 해당 파라미터를 활용하면 좋다.
repetition_penalty or no_repeat_ngram_size
반복되는 문장을 제거하기 위해 repetition_penalty 또는 no_repeat_ngram_size 파라미터를 설정할 수 있는데, repetition_penalty 는 반복되는 토큰에 패널티를 주는 방식이고, no_repeat_ngram_size 는 ngram 을 설정해서 해당 ngram 이 반복되지 않도록 하는 방식이다.
reptition_penalty 는 명확하게 반복을 막는것이 아니며 경우에 따라 반복 자체는 나쁘지 않은 경우도 많기 때문에(e.g. Amazon 서비스에 대한 설명을 하는 봇의 경우 AWS, Amazon 이라는 단어를 서비스 앞에 계속 붙여줘야 한다.), no_repeat_ngram_size 를 사용하는 것이 긴 문장 생성시 더 좋은 결과를 얻을 수 있는 것 같다.
스트리밍
챗UI 를 위해 보통 Streamlit 이나 Gradio14 를 쓰는거 같지만 이 프레임워크들은 모델을 빠르게 테스트 하라고 만든 툴이지 실제 사용자한테 서빙하라고 만든 툴은 아닌 것 같다.
결국 서버는 FastAPI 를 기반으로 직접 만들어야 하는데, 이 때 7B 모델을 512 길이로 GPU 로 일반 추론시 대략 20초 정도가 걸린다. 따라서 스트리밍이 없이 그냥 요청을 받아서 처리하면 사용자 경험이 영 좋지 않기 때문에 스트리밍이 필요하다.
다행히 최근에 huggingface 모델의 generate 함수에서 streamer 파라미터를 지원해주고 있어서 (preview 라 아직 불안정 하지만) 이걸로 스트리밍을 구현할 수 있다.
또한, LLM 기반의 채팅은 이름만 채팅이지 실시간일 필요는 없기 때문에(서버측의 레이턴시가 굉장히 길기 때문에) 웹소켓 보다는 그냥 SSE 로 처리하는 것이 조금 더 효과적인 것 같다.
프롬프트 엔지니어링
프롬프트 엔지니어링 가이드15 를 보면 어떻게 프롬프트를 만들어야 하는지 나와있다. (deelearning ai 사이트에서 앤드류 응 교수가 강의한 무료 강의도 좋다.)
프롬프트 엔지니어링은 LLM 모델이 내가 원하는 결과를 잘 내놓지 않을 때, 내가 원하는 결과를 잘 내놓도록 모델을 조정하는 방법이다.
모델의 파라미터를 업데이트(파인튜닝) 하지 않고 인풋 파라미터만 조정하는 방식이므로 훨씬 빠르고 쉽게 모델을 개선할 수 있다.
다만 프롬프트 엔지니어링은 너무 휴리스틱하고 모델의 크기나 학습된 데이터 형태에 따라서 다르게 조정해야 하기 때문에 일관성이 없다. 이 말은 ChatGPT 에서 쓰던 프롬프트가 Falcon 이나 Alpaca 에서는 동작하지 않을 수도 있다는 의미이다. (실제로도 잘 동작 안함)
특히 프롬프트가 복잡해질 수록 모델의 성능도 좋아져야 하기 때문에 작은 모델의 경우 프롬프트 엔지니어링만으로 원하는 결과를 내기가 더 어렵다.
요새 많이 쓰는 LangChain16, Griptape, Auto-GPT17 등 대부분의 라이브러리 들은 ReAct18 기법을 사용한 프롬프트 엔지니어링 기반으로 동작하고 있다. 따라서 백본 모델의 성능에 따라 동작하던 기능들이 동작하지 않는 경우가 많기 때문에 모델 교체시 주의해야 한다.
모델 성능은 앞으로 계속 우상향하면서 올라가면, 사내에서 용도에 맞게 다양한 크기의 모델을 사용하게 될 수도 있는데 이 경우 프롬프트 엔지니어링을 얼마나 잘 하느냐에 따라 모델을 더 작은 것을 쓸수도 있고 아닐 수도 있게 되며, 이는 프롬프트 엔지니어에 따라 모델크기가 결정된다고 볼 수도 있다.
따라서 좀 더 정형화되어서 모든 모델에 적용할 수 있는 방식이 나와서 프롬프트 엔지니어링을 더 이상 안해도 되는 상황이 왔으면 좋겠다.
토큰 길이
토큰은 토크나이저가 텍스트를 자르는 단위로, 일반적으로 4글자 정도로 예측한다. (정확한 것은 토크나이저를 돌려보면 되며, ChatGPT 나 Claude 같은 서비스형 LLM 들은 모두 토큰길이를 확인할 수 있게 기능을 제공하고 있다.)
현재 라마 모델은 모델 크기에따라 2k 에서 6k 까지 토큰을 처리할 수 있다.
RAG 가 막 활성화되었을땐 토큰 길이를 늘리는 것이 화두였고, 이를 위해 기존의 시그모이드 기반의 포지셔널 인코딩 방법이 아니라 ALiBi 등의 다양한 기법들이 나왔다.
그 결과 현재의 모델들은 엄청나게 긴 프롬프트를 처리할 수 있게 되었고, 이는 엄청나게 큰 컨텍스트를 프롬프트에 담을 수 있다는 뜻이다. 실제로 Claude 나 ChatGPT 도 100k 정도로 엄청 긴 토큰을 처리할 수 있게 되면서, 얇은 책은 청크(chunk) 단위로 자를 필요없이 통째로 프롬프트에 넣어서 처리할 수 있을 정도가 되었다.
하지만 최근 연구들에서, RAG 사용시 프롬프트 길이가 길어질수록 (정확히는 연관문서를 가져오는 개수가 늘어날수록) 정확도가 떨어진다는 결과도 나오고 있고, 프롬프트를 마냥 길게 디테일하게 쓰는 것이 전혀 도움이 안된다는 결과도 나오고 있다.
따라서 이런 자료들을 바탕으로 간결한 프롬프트를 작성하는 것이 비용측면이나 정확도 측면에서 훨씬 좋을 것으로 생각된다.
왜 7B 이 인기인가?
위의 영상에서 현재 7B 가 가장 활발히 연구되는 이유로 연구비용 대비 성능의 균형을 들고 있다.
실제로 대부분의 온프레미시 연구장비 및 클라우드가 16GB vram 을 제공하고 있고, 7B 를 fp16 으로 로드하면 vram 을 14GB 정도 사용하게 되므로, 생성에 필요한 메모리 등을 고려하면 7B 가 가성비상 가장 좋은 모델이 된다.
마치며
최근 공부한 내용중 일부를 정리겸 적은거라 다소 두서가 없지만 이 글에 나온 단어들만 대략 이해하고 있어도 최근 나온 모델을 실행하고 테스트하는 데는 전혀 문제가 없을 것이다.