개발자로서 StableDiffusion 사용을 위해 알아두면 좋은 내용들
2023년 07월 16일 작성TL;DR
코드는 고민중. (허깅페이스 쓰면 잘 되기 때문에)
시작하며
최근 몇 주동안 Stable Diffusion 모델로 프로토타이핑을 진행하게 되었는데,
이미지 생성모델의 특성상 프롬프트가 엄청 중요하지만, LLM 프로젝트에 비해서 프롬프트 엔지니어링을 할 수 있는 부분이 제한적이라 곤란한 부분이 많았다.
본 글에서는 이미 나온 모델을 간단한 파인튜닝 정도만 해서 사용하는 일반 개발자 입장에서 위의 내용을 공부할 때 도움이 될만한 내용을 정리해본다.
디퓨전 모델 (Diffusion Model)
디퓨전 모델의 동작방식과 디테일한 설명들은 이 글1 과 이 글2 에 완벽하게 설명되어 있다.
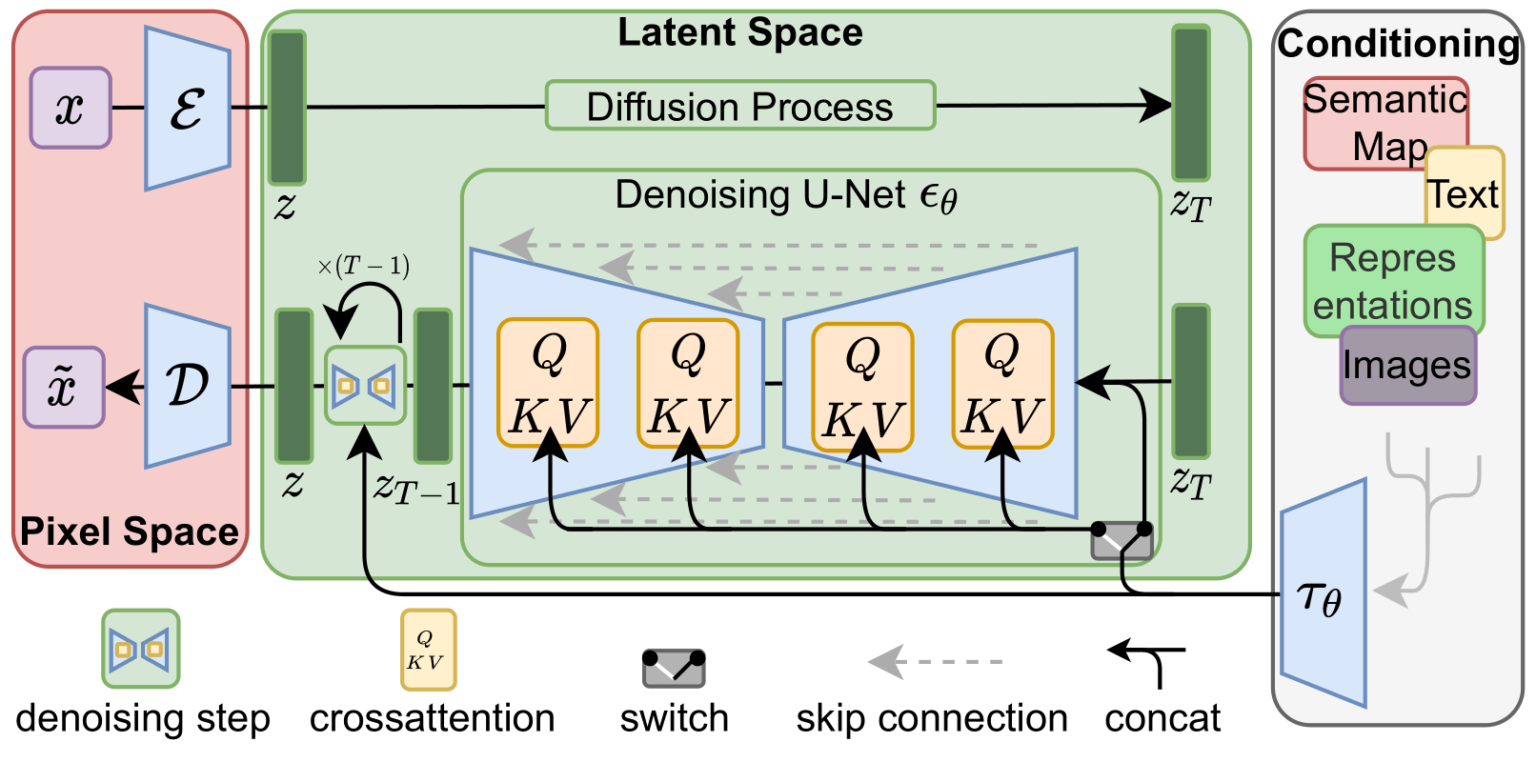
디퓨전 모델을 간단히 설명하면, 컨디션(주로 텍스트) 과 노이즈가 포함된 이미지 를 입력값으로 받아서, 입력 이미지에 얼마나 노이즈가 있는지 노이즈를 예측(디노이즈) 해서 제거함으로써 원본 이미지를 생성하는 모델이다.
여기서 컨디션은 주로 텍스트를 사용하는 편이지만 이미지(Img2Img 모델), Canny Edge / Keypoints(ControlNet) 등 다양한 피쳐들이 있을 수 있으며, 이 역할은 노이즈를 예측할 때 컨디션을 최대한 반영해서 의도한 이미지를 생성하도록 가이드하는데 있다.
텍스트 기반 컨디션을 하는 것이 일반적으로 많이 알려져있으므로, 특별한 언급이 없으면 Text to Image 디퓨전 모델을 기준으로 설명한다.
디퓨전모델은 위의 그림에서 보이듯이, 크게 아래의 3개 모델로 구성되어 있다.
- 가장 좌측에 빨간색 박스인 VAE(Variational AutoEncoder/Decoder) 모델
- 가장 우측에 컨디션부분에서 텍스트를 임베딩하는 CLIP 모델
- 중앙 하단의 노이즈를 제거하는 (denosiing) 부분인 U-Net 모델
VAE
VAE 에 대한 디테일한 설명은 넘어가고 개념적인 부분만 살펴보자.
VAE 는 Pixel Space 를 Latent Space 를 만들고(Encoding) 이것을 원래 Pixel Space 로 되돌리는(Decoding) 역할을 한다.
즉, 대충 512x512 픽셀을 이미지가 담고 있는 정보를 최대한 유지하는 방식으로 64x64 로 다운사이징하여 이후 계산단계에서 계산량을 줄이고, 계산이 끝나고 난 결과를 다시 원래 512x512 크기의 이미지로 되돌리는 역할을 한다고 보면 된다.
인코딩 후 원본 이미지에 노이즈를 주입하게 되는데, 녹색 박스에서 위쪽에 보이듯이(그냥 직선임), 디퓨전프로세스(노이즈 생성) 는 머신러닝과 관계없다.
가우시안 함수로 생성되는 노이즈를 원본 이미지에 스텝(T) 별로 삽입한다.
CLIP / OpenCLIP
CLIP3 은 OpenAI 에서 만든 모델로 텍스트를 임베딩하는 모델이다.
CLIP 모델의 목적은 이미지를 설명하는 텍스트가 주어졌을때 이미지를 잘 설명할 수 있는 임베딩을 만들어내는 것이다.
이를 하기 위해서 (이름에 나와있듯) Contrastive pre training 방식을 사용하는데, 대충 이미지와 해당 이미지를 설명하는 텍스트(캡션) 를 임베딩해서 이미지와 캡션의 유사도를 최대로 올리고 다른 캡션과의 유사도를 낮추는 방식으로 학습을 진행한다.

위의 그림에서 대각 행렬이 이미지와 캡션이 일치하는 경우이므로 해당 값들이 가장 높게끔 학습한다.
OpenCLIP4 은 CLIP 과 비슷한데 모델 사이즈를 키우고 데이터도 더 많이 넣은 버전이라고 보면 된다.
웹에서 크롤링 된 대규모 오픈데이터로 학습하는 것이 목표였기 때문에 캡션 데이터의 품질에 문제가 있었다. 따라서 부트스트래핑 방식으로 학습하면서 데이터의 품질도 같이 끌어올리는 식으로 했기 때문에 부산물로 대규모 캡션 데이터5도 확보할 수 있었다.
여튼 두 모델 다 기본구조는 같기 때문에 임베딩하고 나면 토큰당 768 사이즈의 피쳐를 얻을 수 있고, 이 피쳐를 노이즈가 삽입된 Latent Feature 와 concatenate 한 뒤, U-Net 에서 디노이징 과정을 거치게 된다.
U-Net
U-Net6 은 원래 세그멘테이션 맵을 만들기 위한 CNN 모델이다.
구조는 약간 피쳐피라미드를 연상하게 하는데, 그냥 3x3 Conv 로 피쳐를 뽑고 Max pooling 을 진행해서 피쳐크기를 줄인다. 이후 다시 2x2 Conv 로 up Conv 과정을 거쳐서 피쳐 크기를 다시 키워준다. 그리고 각 크기별로 skip connection 을 통해 피쳐 정보를 크기변화에 무관하게 최대한 보존한다.

이렇게 입력받은 피쳐를 압축했다가 복원하는 과정을 거치면서 (그림에서도 인코더-디코더 그림처럼 표시된다) 세그멘테이션 맵을 만들게 되는데, 이 결과를 통해 노이즈를 예측하고, 노이즈를 이미지에서 지우는 과정을 통해 이미지를 생성한다.

이 과정에서 몇번의 스텝을 거쳐서 노이즈를 예측해서 지울 것인지 정해줘야 하는데, 각 스텝별로 노이즈가 얼마나 분포되어 있을지 미리 정해두는 데 이 분포를 결정하는 것을 스케쥴러라고 한다.
이런 과정을 거쳐서 노이즈를 제거한 피쳐를 VAE 디코더에 전달하여 복원하면 이미지가 생성된다.
Conditioning
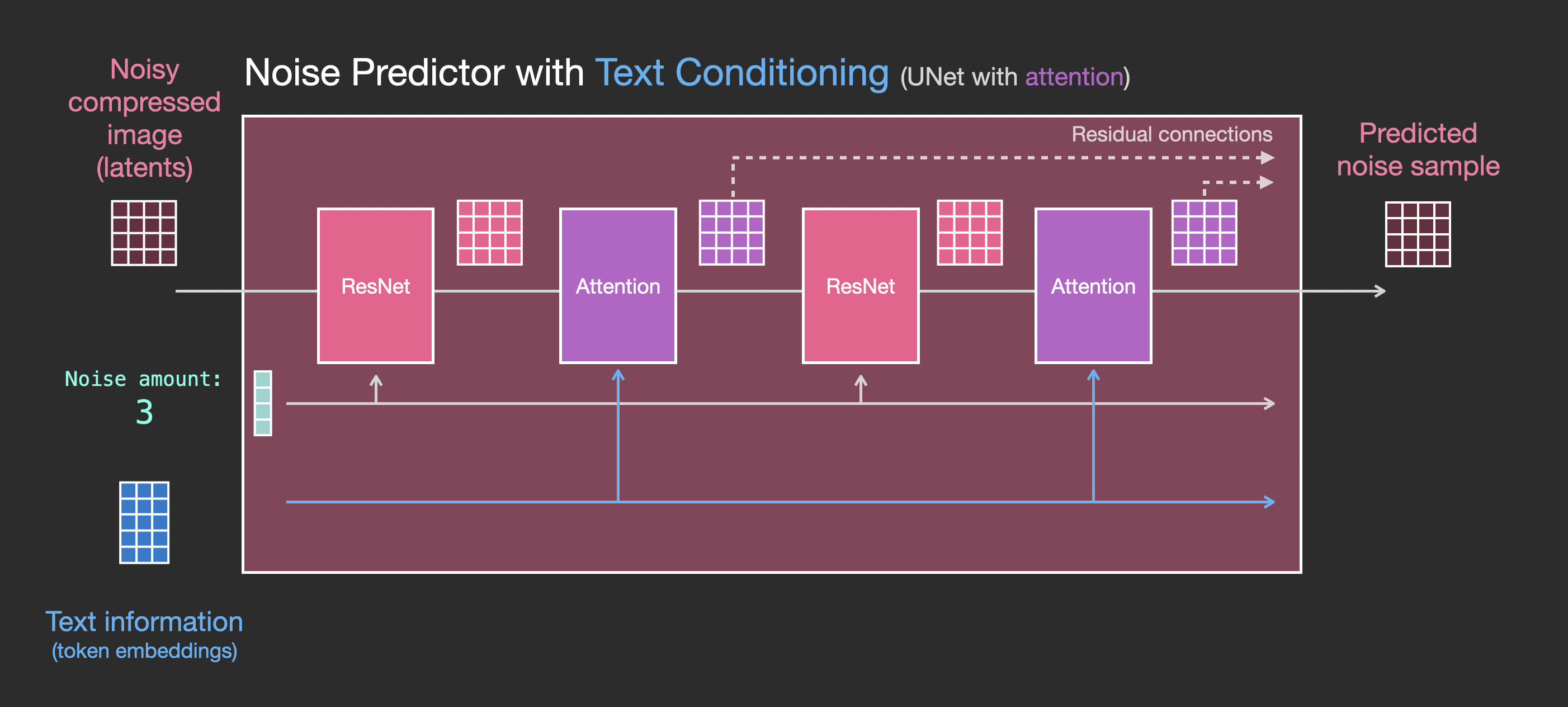
U-Net 에서는 텍스트 등의 컨디션 임베딩을 이용하여 컨디셔닝을 하면서 디노이징을 해줘야 한다. 스테이블 디퓨전에서는 이 부분이 노란색 박스의 크로스어텐션7으로 표시가 되어 있다. 그런데 원래 U-Net 은 CNN 모델이라 크로스어텐션을 사용할 수 없다.
따라서 원래 U-Net 의 컨볼루션 레이어 사이에 어텐션 레이어를 넣어서, 크로스어텐션 방식으로 이미지 임베딩과 컨디션 임베딩을 처리할 수 있도록 구성되어 있다.
Image to Image (Img2Img)
Image to Image 는 Text to Image 와 전혀 다를 것이 없다.
Text to Image 의 입력값중 노이즈가 있는 이미지 를 사용자가 입력하는 이미지로 전달할 뿐이다.
생성할때는 사용자가 입력하는 이미지에 얼마나 노이즈를 주입할 지 (strength) 지정해줄 수 있다. 사용자의 입력 이미지는 strength 크기에 비례해서 노이즈를 갖게 된다. 따라서, strength 가 1 이면 사용자의 이미지가 완전한 노이즈라고 가정하고 노이즈를 예측해서 이미지를 생성하게 된다.
허깅페이스기준 기본 값은 0.8 이며, 전체 면적의 80% 를 가우시안 분포의 노이즈가 덮고 있다고 가정한다.
Fine-tuning
스테이블 디퓨전은 photo realistic 한 이미지들을 메인으로 학습했기 때문에 (아닌 이미지도 많지만) 스타일을 바꾼다거나, 특이한 자세나 일반적으로 잘 쓰이지 않는 형태들을 만들어내기 어렵다.
예를 들어, 옛날 전화기의 송수화기 이미지를 만들려고 telephone handset 형태를 만들려고 하면 모델은 해당 형태를 만들지 못한다. (대부분의 경우 스마트폰을 만들어내거나 옛날 전화기 전체 모양을 만들게 된다.)
따라서 모델 자체가 생성하지 못하는 특정한 형태를 만들어내려면 파인튜닝을 해줘야하는데, 허깅페이스를 사용하면 데이터 생성부터 학습까지 매우매우 쉽게 할 수 있다.
파인튜닝시 중요한 파라미터는 아래 2개 정도이다. 나머지 파라미터들은 대부분 전체 퀄리티에 큰 영향을 주지 않는 편이다. (lr_scheduler 가 cosine annealing 이 아닌 경우)
- 학습 스텝 (max_train_steps)
- 학습 계수 (learning_rate)
Dataset
허깅페이스는 datasets8 라이브러리를 통해 데이터셋을 쉽게 만들고 허깅페이스 허브에 등록할 수 있게 해준다.
지금까지의 내용을 통해 유추할 수 있지만, 스테이블 디퓨전 학습을 위해서는 이미지와 캡션이 모두 필요하다.
대부분 이미지는 쉽게 구할 수 있지만 캡션은 직접 만들어야 할텐데, 대규모 이미지의 캡션을 처음부터 만드는 것은 굉장히 고달픈 일이다.
이 때 사용할 수 있는 모델이 세일즈포스의 BLIP29 와 InstructBLIP10 모델인데, 멀티모달이 대세가 되고 있는 시점에 한번 살펴볼만한 모델이다. 해당 모델은 대략 트랜스포머 기반 이미지 임베딩 모델(ViT) 와 트랜스포머 기반 LLM 을 이용하는 2 스테이지 모델인데, 두 모델은 건드리지 않고 둘의 사이를 이어주는 또다른 트랜스포머 모델(Q-Former) 를 학습해서 이미지에 대한 캡셔닝, 리즈닝 등의 다양한 작업을 할 수 있는 모델이다.
위 모델과 다른 이미지 관련 모델들을 섞어서 잘 사용하면 충분히 디테일한 캡션을 생성할 수 있다.
Dreambooth
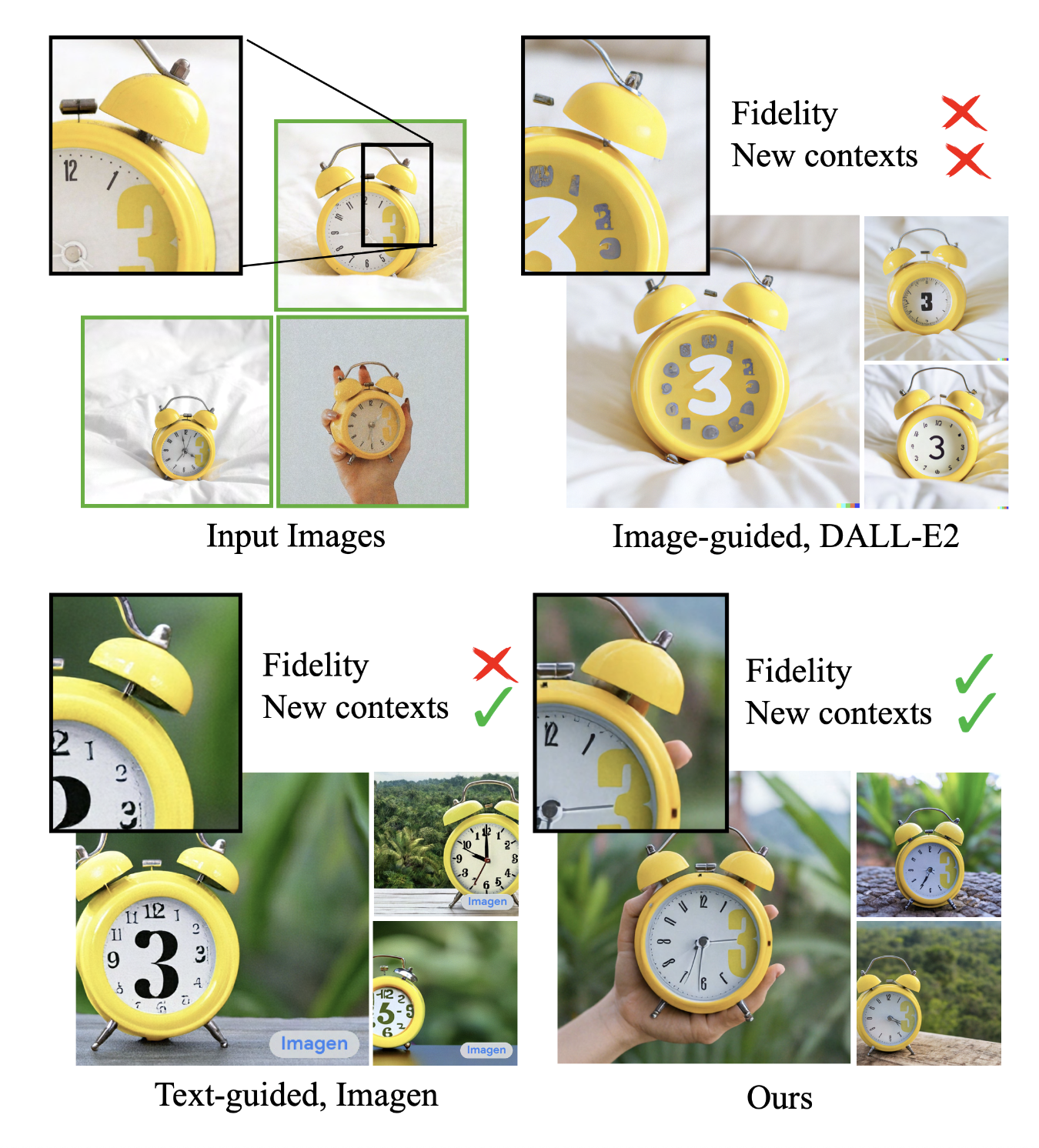
드림부스11 는 구글리서치에서 발표한 학습방법인데, 대략 사용자의 엔티티에 해당하는 이미지 (위 이미지에서는 3시가 노란색 큰 글자 시계) 를 특정 토큰에 오버피팅 시켜서 해당 엔티티를 다양한 형태로 변환할 수 있는 방식이다.
비슷한 용도로 사용되는 학습 방식으로 Textual Inversion12 방식이 있는데, 둘의 큰 차이점은 Textual Inversion 은 원본 모델을 건드리지 않고 어댑터를 추가해서 학습하는 방식이고, 드림부스는 원본 모델을 파인튜닝 하는 방식이다. (드림부스는 텍스트인코더도 학습해서 성능을 더 끌어올릴 수 있다.)
또한 드림부스 방식은 regluarization images 라는 방식을 통해서 해당 토큰외의 다른 부분이 영향이 가는 것을 막을 수 있다. (내 강아지 엔티티로 sksks dog 라는 토큰을 쓸 경우 dog 에는 영향이 가지 않도록)
마지막으로 논문을 포함하여 대부분 예제들은 위에 소개한 이미지처럼, 특정 토큰에 엔티티를 매핑하는 식으로 학습하지만, Arcane Diffusion13 같은 모델들을 보면 스타일을 변환하는 형태로도 잘 동작하는 것을 확인할 수 있다.

위의 이미지는 디즈니 공주들을 아케인 애니메이션 스타일로 변환한 것인데, 95장 이미지와 8000스텝 정도로 학습했다고 한다. 이 수치들은 원래 드림부스 가이드(12 장 정도의 이미지에 200~800스텝) 과 매우 상이하기 때문에 여러 실험을 통해 다양하게 쓸 수 있는 학습방법이다.
Generation
text2img 생성에 신경쓸만한 내용은 아래 3개 정도이다.
- denosing steps (steps)
- scheduler (or sampler)
- guidance scale (cfg)
Denosing Steps (디노이징 스텝)
스텝은 보통 20 ~ 32 정도를 기본으로 두고 생성한 뒤에, 이미지에 노이즈가 껴 있으면 늘려주면 된다.
일반적으로는 아래 설명할 cfg 가 커지면 같이 커지게 된다.

또한 위의 그림에서 볼 수 있듯이 스텝이 커진다고해서 이미지가 더 퀄리티가 좋아지는 것이 아니며, 사용하는 샘플러에 대해 적절한 스텝크기를 찾아야 한다.
Scheduler (혹은 샘플러)
스케쥴러 또는 샘플러14는 지정된 매 스텝 마다 노이즈를 얼마나 있다고 예측할 것인가를 결정하는, 노이즈의 분포도라고 볼 수 있다.

위의 그림을 기준으로 설명하면, 디노이징 스텝이 30 일 경우 U-Net 은 각 스텝별로 해당 비율 만큼의 노이즈가 포함되어 있다고 예측한다.
샘플러에서 알아둬야할 키워드는 크게 2가지 이다.
- Ancestral samplers
- Karras
Ancestral sampler 는 각 스텝별로 노이즈를 추가한다. 따라서 스텝을 아무리 올려도 수렴하지 않는다. ancestral sampler 들은 다음과 같이 이름 뒤에 a 가 붙는다.
- Euler a
- DPM2 a
- DPM++ 2S a
- DPM++ 2S a Karras
Karras 는 nvidia 직원이름인데, 마지막 스텝에서 노이즈가 0 이 되게끔 설계된 분포도보다 마지막에 약간의 노이즈가 있게끔 설계한 분포도가 더 성능이 좋다는 내용의 논문을 썼다.

즉, 위와 같은 분포가 Karras 분포이고, karras 분포를 반영한 샘플러들은 이름 뒤에 karras 가 붙는다.
허깅페이스의 경우 use_karras_sigmas 라는 파라미터를 주면 사용할 수 있다.
Classifier free guidance (cfg)
CFG 에 대한 내용은 이 영상15에서 잘 설명하고 있다.
예전 스테이블 디퓨전 모델은 컨디셔닝을 위해 분류기(Clasffier) 를 사용했다. 하지만 거의 무한한 클래스를 커버하기 어렵고, 노이즈가 낀 이미지를 분류하는 분류기를 학습하기도 어렵다.
CFG 라는 방식을 통해 디퓨전 모델에서 클래스 없이도 컨디션을 반영할 수 있도록 개선할 수 있었다.
즉, 위의 내용을 통해 보면 cfg 가 컨디션(텍스트)에 영향을 주는 내용이라는 것을 알 수 있다. cfg 를 1.0 이상으로, 크게 설정할 수록 이미지에서 노이즈를 예측하고 제거할 때 컨디션으로 주어진 텍스트를 더 강하게 반영하게 된다.
특히 img2img 생성시, 사용자가 입력한 이미지를 노이즈로써 사용하는 것과 동일하기 때문에 cfg 를 높은 값(15+)으로 설정하면 strength 를 낮게 주더라도 사용자 입력 이미지를 거의 무시하고 프롬프트로 주어진 텍스트를 강하게 반영하게 된다.
Evaluation
파인튜닝을 할 때 wandb 를 이용해서 눈으로 보면서 학습하는 것이 가장 확실하겠지만, 실제로 HPO (Hyperparameter Optimization) 을 위해서 수십개의 작업을 돌리려면 한계가 있다. (그리고 세이지메이커에서 HPO 를 하려면 메트릭을 설정해줘야 한다.)
GAN 모델들은 성능을 평가할 때 보통 FID16 를 사용한다. 드림부스 논문에서도 FID 를 사용하고 있다. (논문의 예제에는 프롬프트가 몇개 없는데 실제로는 훨씬 많은 프롬프트가 있어야 한다.)
이 FID (Frechet Inception distance) 는 IS (Inception Score)17 의 문제점을 보완하기 위해서 만든 방법이다.
허깅페이스를 통해 스테이블 디퓨전을 학습하려면 FID 부분을 직접 구현해야하지만 크게 어려운 내용은 아니며, 실험해보면 FID 으로 평가해도 큰 무리 없는 것 같다. (프롬프트를 많이 넣어줘야한다..)
Versions (1.5 vs 2.1)
현재 civitai 같은 곳에 올라온 모델들은 대부분 1.5 인데 최신버전은 2.1 이다.
둘의 차이를 정리하려면 아티클 하나를 따로 써야할 정도로 내용이 많다.
짧게 가이드 하자면, 별다른 튜닝없이 생성하는 경우에는 1.5가 성능이 훨씬 잘 나온다. 하지만 본인이 프롬프트 엔지니어링을 할 수 있다면 2.1 도 1.5 와 성능이 비슷하게 나올 수 있다.
1.5 는 CLIP 모델을 쓰고 2.1 은 OpenCLIP 모델을 쓰기 때문에 텍스트 컨디셔닝 능력이 2.1 이 훨씬 좋다. (negative prompt 기능과 파인튜닝 했을때 텍스트를 반영하는 능력 등이 더 좋다.)
따라서 텍스트를 좀 더 정확히 반영하는 엄밀한 컨디셔닝이 필요하다면 2.1 을 써야하고, 수십장 이상의 이미지를 생성해서 느낌이 괜찮은 한두개만 찾아도 된다면 1.5를 써도 무방하다.
마치며
현재 기준 0.18.2 가 최신버전인데, lr_schduler 가 cosine annealing 스케쥴러를 썼을때 스텝수를 아직도 변경못하게 되어 있다.
실제로 lr_scheduler 를 cosine restarts 를 잘 쓰면 성능이 올라가는데 restart cycle 을 지정하려면 그냥 코드 포킹해서 써야한다. (그리고 어차피 sagemaker 에서 학습하려면 포킹해서 커스텀 도커 만드는게 편하다.)