Robotics + AI 트렌드 대충 정리
2024년 03월 29일 작성TL;DR
- Pre-trained Foundation Model for Robotics
- Leverage Foundation Model for Robotics
시작하며
몇달전 알게된 Rabbit R1 과 MultiOn 이 후 개인적인 관심사는 AI Agent 이다.
Figure1 을 보고 나서 찾아보니 Agent 가 가장 진지하게 연구되는 분야가 로보틱스 인 것 같다.
나처럼 아예 로보틱스에 대한 지식이 없는 개발자들을 대상으로, AI 가 어떻게 로보틱스 쪽을 혁신하고 있는지 알아두면 좋은 내용을 간단히 정리해본다.
Trend
CS 에서 새로운 기술은 기존의 한계를 극복하기 위해서 나오는 경우가 많다.
따라서 CS 에서 새로운 분야에 들어갈 땐, 최신의 기술이 해결하고자 하는 바를 파악하고 거기서부터 역으로 돌아가는 것이 가장 효율적이라고 생각한다.
따라서 로보틱스와 AI 에 대한 최신의 트렌드를 먼저 파악하는 것으로 출발하는 것이 좋을 것 같다.
이런 관점에서 전체적인 그림을 그리기 가장 좋은 영상은 Jim Fan 의 TED 영상1 이다.
Skill 과 Embodiment 를 축으로 로보틱스와 AI (특히 Agent) 의 발전방향에 대해서 설명해주는데, 가장 간결하고 명확하게 설명해주는 자료라고 생각한다.

Skill 은 새로운 툴을 에이전트가 스스로 만들어낼 수 있는 능력이고, Embodiment 는 새로운 몸을 에이전트가 적응할 수 있는 능력이다.
Voyager2 라는 실험을 통해 Skill 생성을, Eureka 라는 실험을 통해 Embodiment 적응에 대한 실험을 했었고, 결과가 꽤 성공적이었다.
최종적으로 추구하는 방향은 이 둘을 모두 아우르는 Foundation Agent 을 만드는 것이라고 한다.
Jim Fan 은 위의 내용에서 조금 더 진행된 내용을 이번 GTC 에서 발표3했는데, 해당 내용을 같이 보면 좋다.
시간이 좀 흘렀지만, 전체적인 방향성이 기존과 같다는 점과 이번에 발표한 GR00T 를 보면, 올바른 방향으로 가고 있다고 판단하는 것 같다.
최근 딥마인드에서 발표한 SIMA4 도 분야가 다르지만 비슷한 느낌인데, 결국 다양한 Skill 과 Embodiment 에 대해 적응가능한 Agent 를 만들어내는 방향으로 진행하고 있는 것 같다.
이런 Foundation Agent 로 가기위한 로드맵에 대한 상세한 내용을 다루고 있는 논문5이 있다. 좀 더 자세한 내용을 원한다면 해당 논문을 참고하는 것이 좋을 것 같다.
Other trajectories
NVidia 뿐아니라 딥마인드도 로보틱스+AI 를 오래전부터 진행해오고 있다.
스탠포드 강의에 서6 알 수 있듯이, 딥마인드는 오래전부터 정말 다양한 방식으로 로보틱스 실험을 해오고 있었는데, 최근 RT-X 데이터셋7 을 봤을 땐 딥마인드도 Foundation Agent 방식을 진행하고 있는 것 같다. (다만 자사 제품인 everydayrobots 를 메인으로 실험하고 있어서 embodiment 적응에 대한 실험은 어느정도 인지 알 수 없다.)
앞서 살펴본 Foundation Agent(정해진 용어가 없어서 현재 Generalist Robotics Agent 등 다양하게 불린다.), 가 현재 가장 유망해보이는 보이는 방향은 맞지만 유일한 방향은 아니다.
스탠포드의 강의8 를 보면 학계는 에이전트보다는 모델을 중심으로 연구가 진행되고 있다. 하지만 Code as Policies9, Learning to Reward10 같은 기존 모델을 활용하고 파인튜닝을 배제하거나 최소화하는 방식들이 나오면서 에이전트에 대한 관심도 높아지고 있다.
또 이와 별개로, Mobile ALOHA, DROID 와 같이 모방학습 (Imitation Learning) + 강화학습 (Reinforcement Learning) 을 이용한 하이브리드 (Hybrid) 학습방식에 대한 연구도 활발히 진행되고 있다.
기존 모방학습은 리워드를 정의할 필요 없이 데이터만 많이 모아서 학습이 가능하다는 장점이 있지만, 주어진 데이터보다 더 나은 방식으로 움직이기 어렵고(sub-optimal) 데이터를 벗어난 환경에서는 적응이 어렵다는 단점이 있다(hard to generalize).
반면 강화학습은 리워드 함수와 정책(policy) 를 정의하기 위해 도메인 지식이 필요하고, 이렇게 사람이 작성한 리워드 함수와 정책이 최적이 아닐 수 있으며, 학습방법의 특성상 온라인 학습 방식이 강제된다. 대신 학습 데이터를 벗어난 환경에서도 적응이 가능하다는 장점이 있다.
하이브리드 방식은 위의 두 방식을 결합하여, 모방학습으로 초기 정책을 학습하고, 강화학습으로 리워드 함수를 학습하는 방식으로 연구가 진행되고 있다.
Foundation Model
결국 전체적인 흐름은 Foundation Agent 를 만드는 것이라고 정리할 수 있을 것 같다.
그리고 이 Foundation Agent 를 만들기 위해서는 Foundation Model for Robotics 가 필요하며 이 Foundation Model 을 활용하는 방법은 크게 아래의 2개로 나눠 볼 수 있다.
- Pre-trained Foundation Model for Robotics
- Leverage Foundation Model for Robotics
그리고 위의 방식들은 공통적으로 강화학습과 Self-reflextive code generation (e.g. Reflexion11, LATS12) 를 어떤 식으로든 이용하고 있다.
각 방식에 대해 간단히 살펴보고 마친다.
Pre-trained Foundation Model for Robotics
이 방식은 로보틱스를 위해 FM (Foundation Model) 을 학습하는 것이다.
대표적인 예가 구글의 RT-1, RT-2 모델이다.7 (RT = Robotic Transformer)
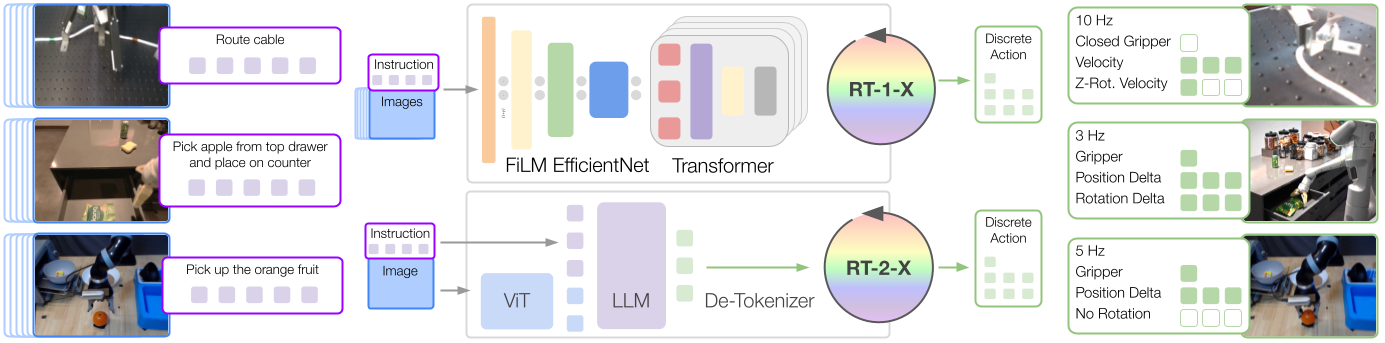
멀티모달 데이터와 인스트럭션(planning), 로봇의 액션(control) 데이터를 입력으로 받을 수 있는 트랜스포머 모델을 학습하여 특정 로봇을 위한 Foundation Model 을 만드는 것이다.
위의 모델은 현재 구글이 everydayrobots 라는 로봇의 액션만 학습하기 때문에 Embodiment 적응에 대한 실험은 따로 진행하고 있지 않다고 볼 수 있으므로, Foundation Agent 에 대한 연구는 아니라고 생각될 수 있다.
하지만 MS 의 연구13를 보면, 2개의 서로 다른 도메인의 low-level 액션을 학습시킨 FM 모델은, 또 다른 도메인의 high-level instruction 으로 파인튜닝 하면 action 에 대한 적응이 빠르게 이루어진다는 것을 보여주고 있다.
또한 이후 나온 RT-X7 데이터셋으로 학습된 RT-1, RT-2 모델을 다른 도메인의 instruction 으로 파인튜닝하면, embodiment 적응이 가능한 Foundation Model 을 만들 수 있을 것으로 보인다.
해당 방식에서 가장 최근에 실제적인 결과를 보여주는 사례가, Covariant 가 발표한 RFM-114 이다.
RFM-1 은 8B 파라미터를 가진 멀티모달(텍스트, 이미지, 비디오, 로봇동작 액션) Transformer 모델로, RT 시리즈와 모델 아키텍쳐 측면에서는 비슷한 아이디어지만 비해 훨씬 더 앞서있는 방식이다.
RFM-1 모델은 SORA15 와 같이 현재 씬에 대해서 액션의 수행결과를 예측하는 영상을 생성하고 해당 영상에 맞춰 액션을 취할 수 있다. 즉, Covariant 도 SORA 와 같이 intuitive physics 를 학습하여 영상을 생성하는 모델을 가지고 있고, SORA 의 첫 기술리포트에서 언급한 대로 SORA 는 물리법칙을 기계가 시뮬레이션 하게 하는 과정에서 나온 side effect 라고 볼 수 있다.
(앞서 GTC 영상을 비춰볼 때 NVidia 도 해당 모델을 가지고 있거나 학습 중인 것 같다. 또한 Meta 도 V-JEPA16 모델을 생각해볼 때 유사한 모델을 만들 수 있는 능력이 있을 것 같다.)
Leverage Foundation Model for Robotics
LLM 의 Emergent abilities 에 대한 연구를 다룬 논문17 에서는, 모델이 특정크기를 넘어서면 작은 모델은 하지 못했던 능력이 갑자기 생긴다는 것을 발견했다.
위의 모델들의 크기는 66M 부터 8B 정도로, 정말 작은 크기의 모델들이다. 해당 모델들은 일정작업은 잘 해내는 것으로 보이지만, 좀 더 어려운 작업을 방법으로 해결하기 위해서는 모델 크기를 emergent 가 나타날 때까지 키울 수 밖에 없을 것이다. (RT-2 논문에서도 더 큰 모델을 사용하면 더 좋은 결과를 얻을 수 있다고 언급하고 있다.)
다른 방법으로는 이미 emergent 임계치를 넘은 크기의 모델을 사용하는 방법이 있고, 이 방법이 지금 소개하려는 방식이다.
현재로서는, Claude, GPT-4 와 같이 1.5T 이상의 파라미터 크기를 가진 모델이 가진 emergent behavior 를 로보틱스에 활용하려면 주어진 모델을 파인튜닝 없이 그대로 이용할 수 밖에 없다.
다행히도 In Context Learning18 방식을 이용하면 파인튜닝 없이도 모델에 새로운 지식을 추가할 수 있다.
Code as Policies9, Learning to Reward10, SayCan19 같은 실험들을 통해 거대한 모델을 활용하여 로봇의 행동 코드 또는 RL 에 사용되는 보상함수를 LLM 을 통해 만들어내는 것이 가능하며(그리고 더 optimal 하다), 이를 이용해 로봇이 high-level instruction 을 따라 작업을 완료하게 할 수 있다는 것을 보여주고 있다.
아직 여러가지 제약으로 메인스트림은 아닌 것 같지만, 충분히 연구해볼 만한 분야인 것 같다.
마치며
결국 Robotics Foundation Agent 를 직접 만들거나, 혹은 NVidia 든 구글이든 현재의 ChatGPT 처럼 Foundation Agent 를 공개한다면 그것을 활용하기 위해서 준비가 되어 있어야 한다. GTC 세션들을 보면 많은 외국 회사들은 이미 Nvidia Omniverse 등을 통해 대비하고 있는 회사도 있는 것 같다.
개인적으로는 이런 준비의 일환으로, 트랜스포머 모델을 원하는 대로 고쳐서 학습시킬 수 있는 능력이 필요할 것 같다. 남는 시간에 트랜스포머를 만들어보고 학습하는 것을 해보고 있는데20 요새는 툴들이 좋아져서 생각보다 어렵지 않고 재미있는 것 같다.