AI 에이전트 시스템을 설계할 때 알아두면 좋은 내용
2024년 08월 24일 작성TL;DR
- 에이전트 시스템은 트레이싱 필수
시작하며
요즘 에이전트 기반으로 만들고 있는게 있는데, 백오피스 같은걸 만들때 어떤 부분들이 어떻게 확장되어야 할 지 애매한 부분이 많았다.
본 글에서는 AI 에이전트 시스템의 종류를 대략(내 맘대로) 분류해보고, 해당 시스템을 설계할 때 알아두면 좋은 내용을 정리해본다.
Thinking, fast and slow
에이전트 관련된 글에서 자주 인용하는 것이 Daniel Kahneman의 Thinking, fast and slow 에서 소개된 두 가지 시스템이다.
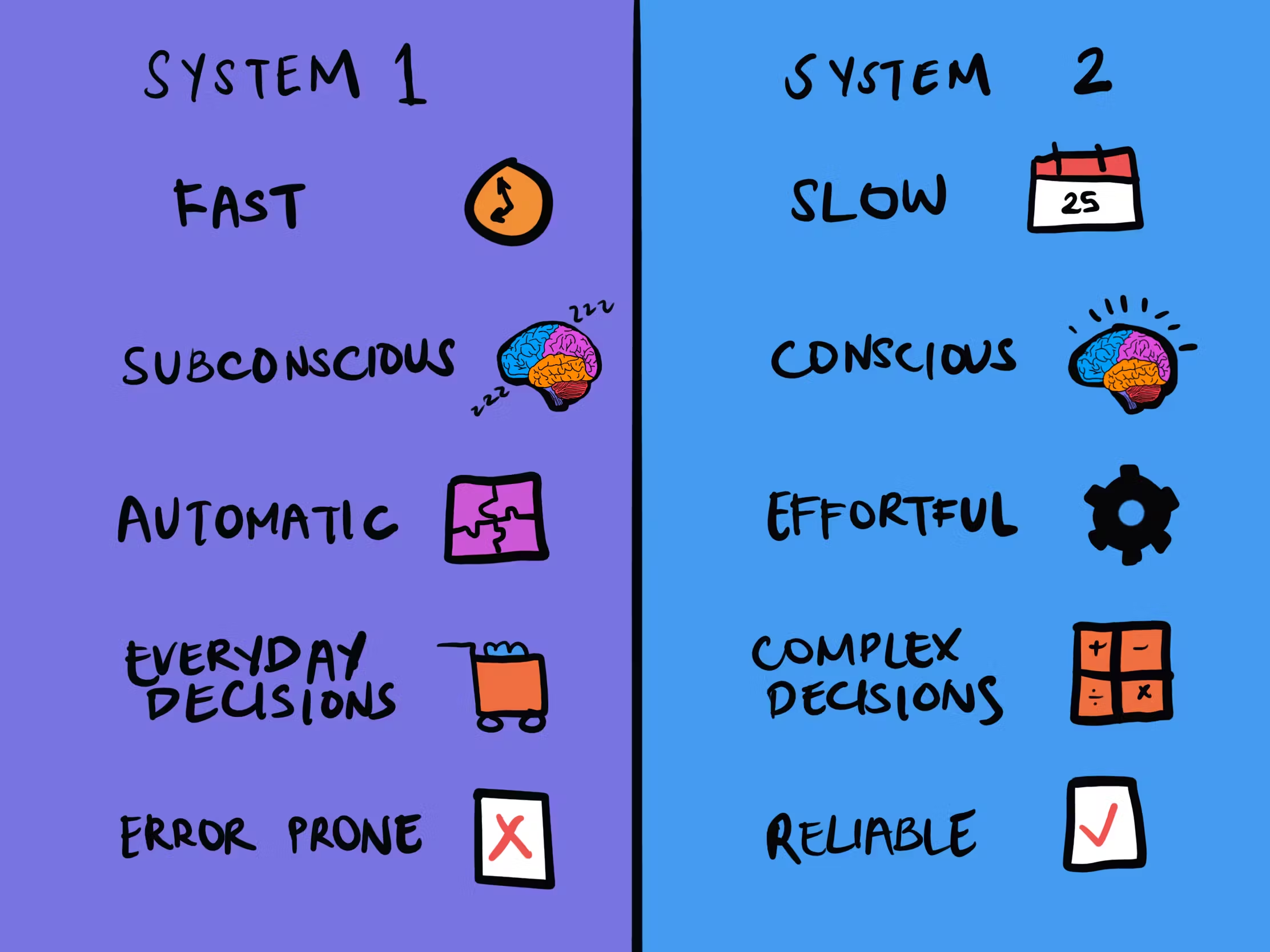
이게 에이전트 기반 시스템과 기존 시스템의 차이점을 이해할 때 유용한 것 같아서, 여기서도 붙여본다.
쉽게 말하면 System 1은 빠르고 직관적인 판단을 하는 시스템으로 일반적인 챗봇 시스템이라고 볼 수 있다.
반면 System 2는 느리고 논리적인 판단을 하는 시스템으로 ReAct 기반의 AI 에이전트 시스템이라고 볼 수 있다.
그리고 좋은 의사결정을 위해서는 이 두 시스템을 적절히 사용하는 것이 중요하다.
AI 기반 시스템 분류
단일 프롬프팅 시스템 (System 1)
- 단일 프롬프트를 기반으로 인풋에 대한 아웃풋을 한 번의 처리로 바로 생성한다.
- RAG (Retrieval augmented generation) 등의 기법으로 외부 저장소에서 컨텍스트를 가져오거나, CoT (Chain of thought) 등의 기법으로 간단한 사고 과정을 추가할 수 있다.
- CoT 과정이 복잡할 경우, 사고 과정을 잘 못 만들거나 혹은 해당 과정을 잘 따르지 않는 경우가 생긴다.
- 생성 속도가 빠르지만 에러율이 높다.
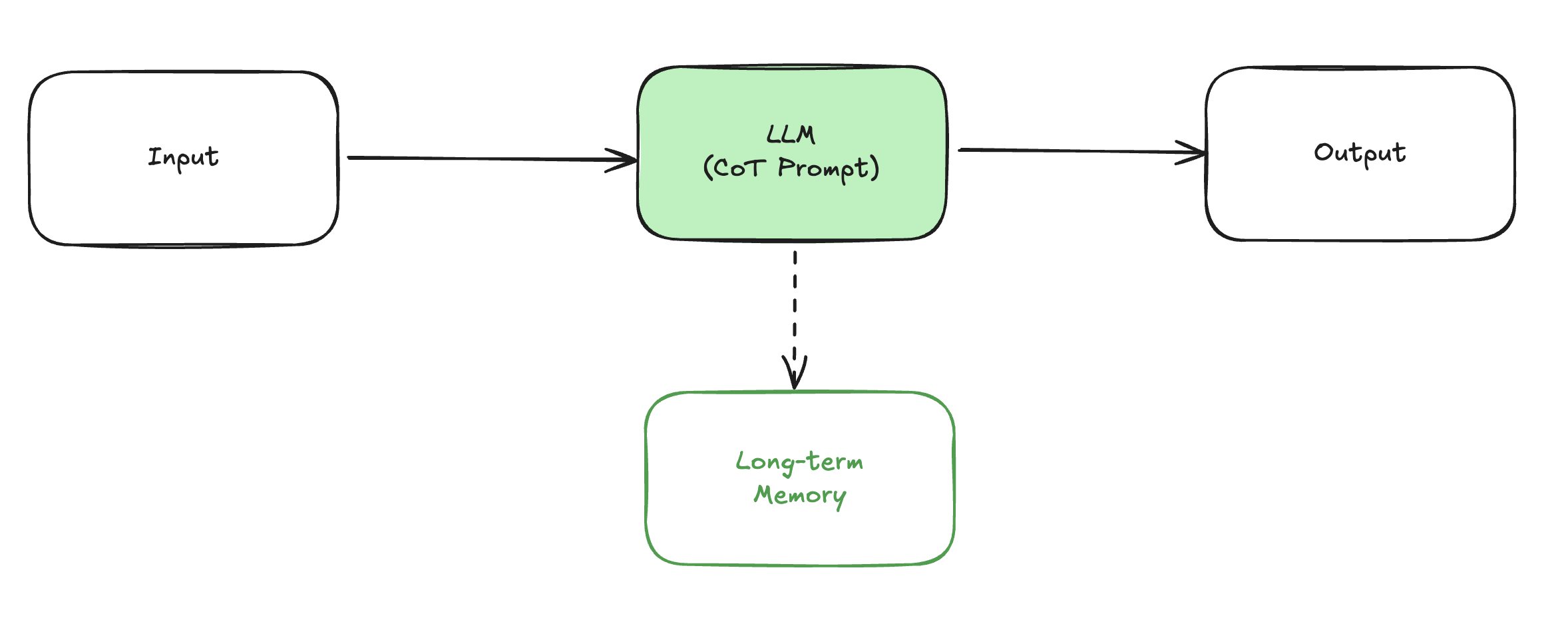
프롬프트 체이닝 시스템 (Extended System 1)
- 여러 프롬프트를 이용하여 생성하지만 각 단계는 단일 프롬프팅 방식과 다르지 않다. (1번의 패스로 생성)
- 이전 프롬프트의 결과를 다음 프롬프트에 컨텍스트로 전달하여 생성한다.
- 주로 CoT 과정이 복잡할 경우 해당 사고 과정을 나눠서, 단순화 시키는 용도로 사용한다.
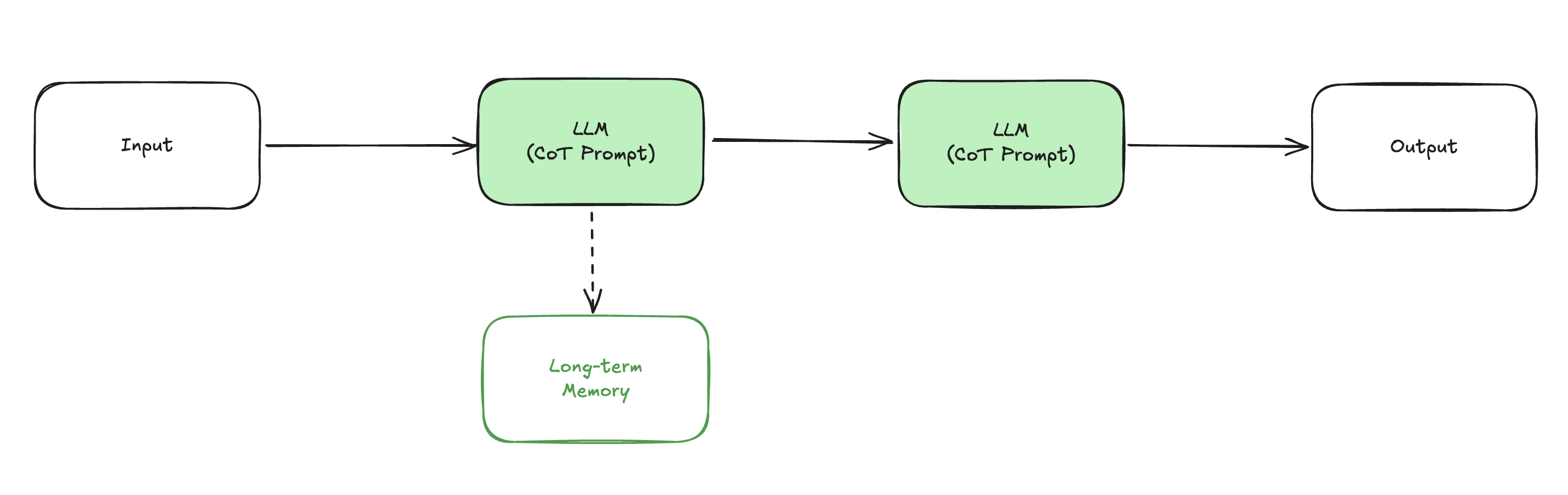
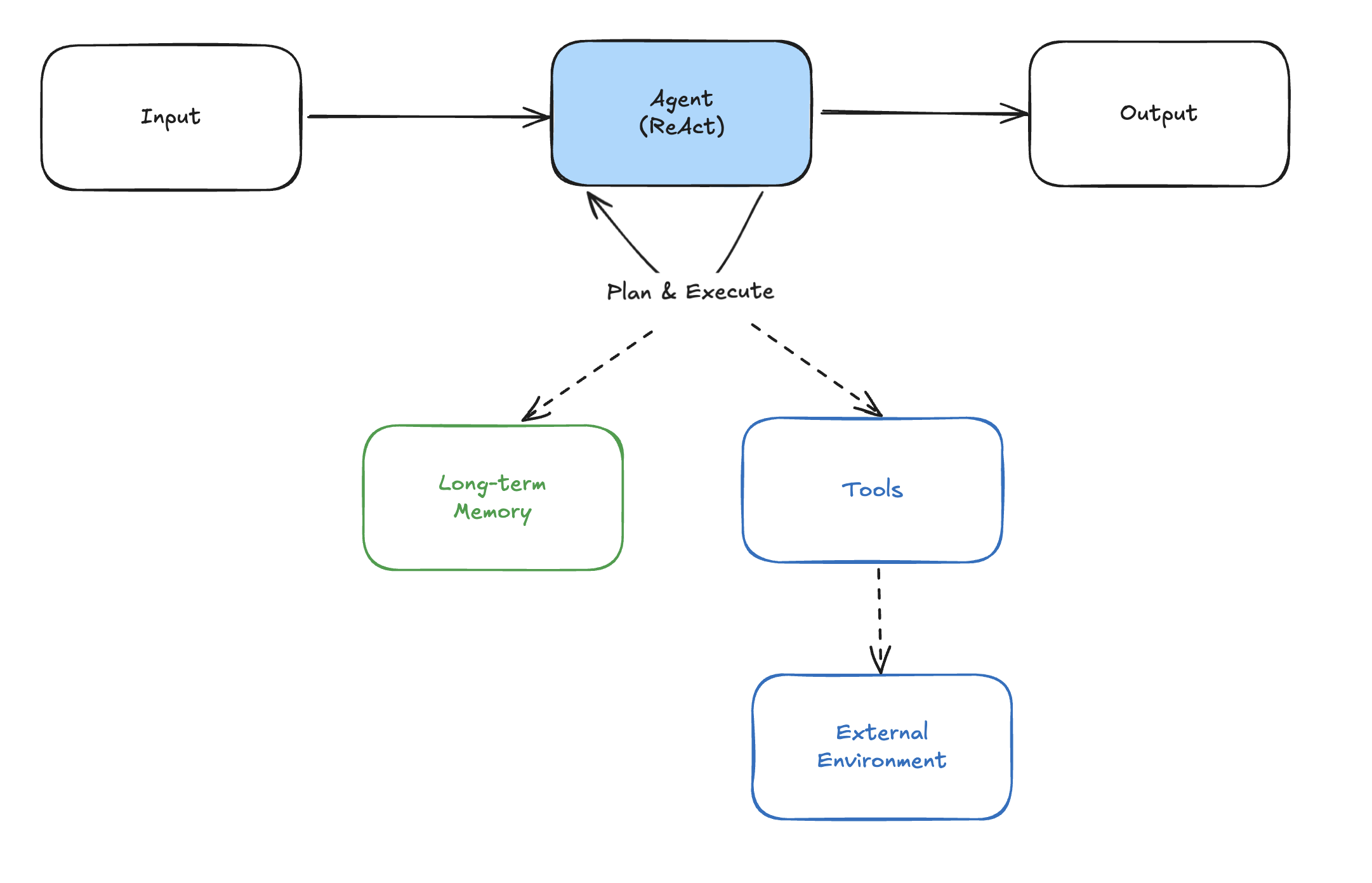
단일 AI 에이전트 시스템 (System 2)
- AI 에이전트란 특정한 작업을 주어진 리소스를 이용하여 완료할 수 있는 인공지능 기반 프로그램 이다.
- 스스로 추론할 수 있는 AI 에이전트를 통해, 특정 작업에 대한 결과물을 생성한다.
- 스스로 추론하는 기능을 구현 하는 방법은 크게 2가지가 있다.
- Semantic Routing + StateMachine 등의 방식으로 흐름을 제어한다.
- ReAct(Reasoning and Acting), Plan & Execute 등의 방식으로 구현한다.
- Semantic Routing + StateMachine 등의 방식으로 흐름을 제어한다.
- 추론과정에 추가적으로 필요한 정보를 획득하기 위해 외부 환경과 상호작용 할 수 있는 도구들을 사용(tool calling) 할 수 있다.
- 해당 도구를 통해 주로 실시간 데이터를 획득하는 용도로 사용한다.
- 추론 과정을 에이전트가 스스로 계획하기 때문에 생성속도가 느리며, 최악의 경우에는 결과를 내지 못할 수도 있다. (예, 무한루프)
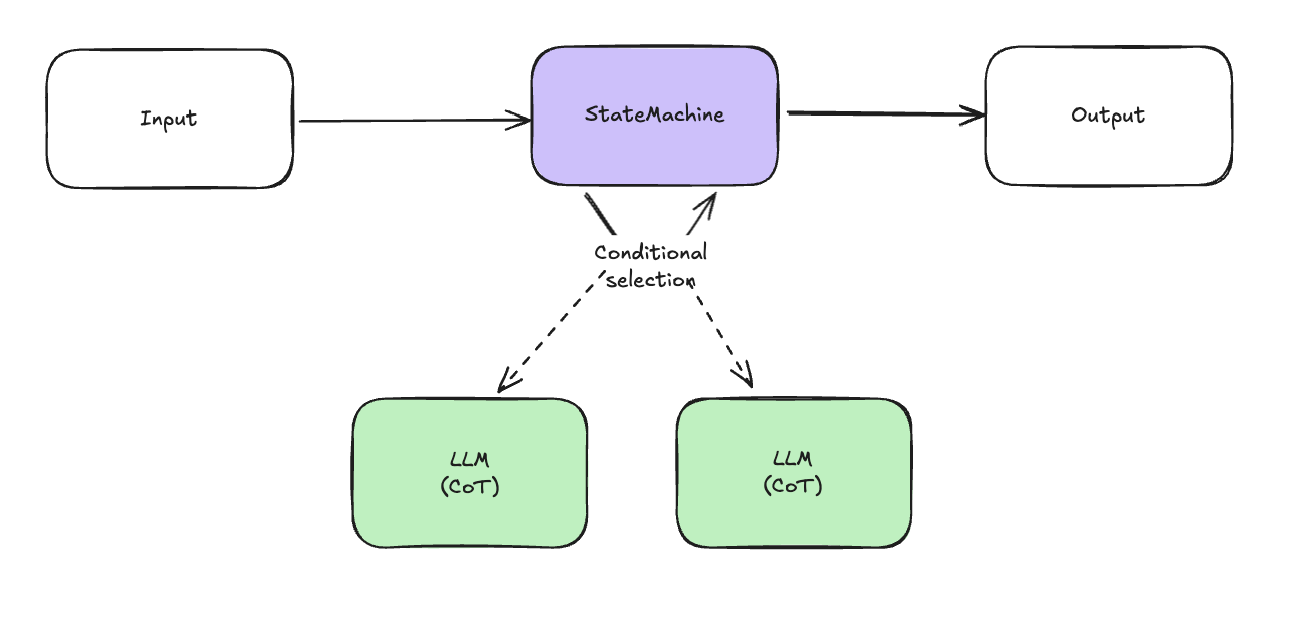
멀티 AI 에이전트 시스템 (Extended System 2)
- 일반적으로 AI 에이전트는 하나의 작업을 잘 처리하도록 설계된다.
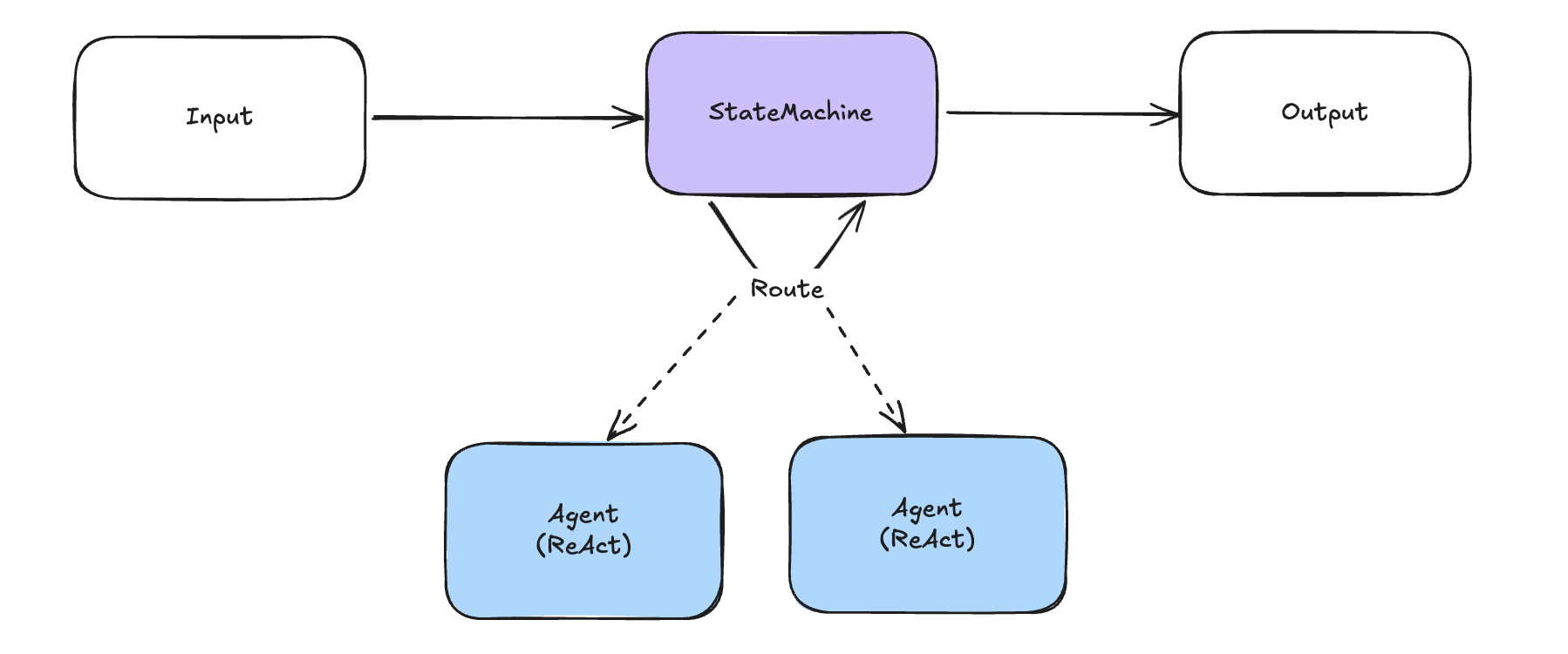
- 여러 AI 에이전트가 여러 작업을 나눠서 처리한 뒤 취합하는 방식으로 더욱 복잡한 문제를 풀 수 있는 시스템이다.
- 여러 에이전트를 조율하기 위해 크게 2가지 방식을 사용한다.
- 상태의 전이를 상태 머신을 통해 미리 설계한다.
- 미리 설계된 흐름에 따라 에이전트간의 통신을 제어한다.
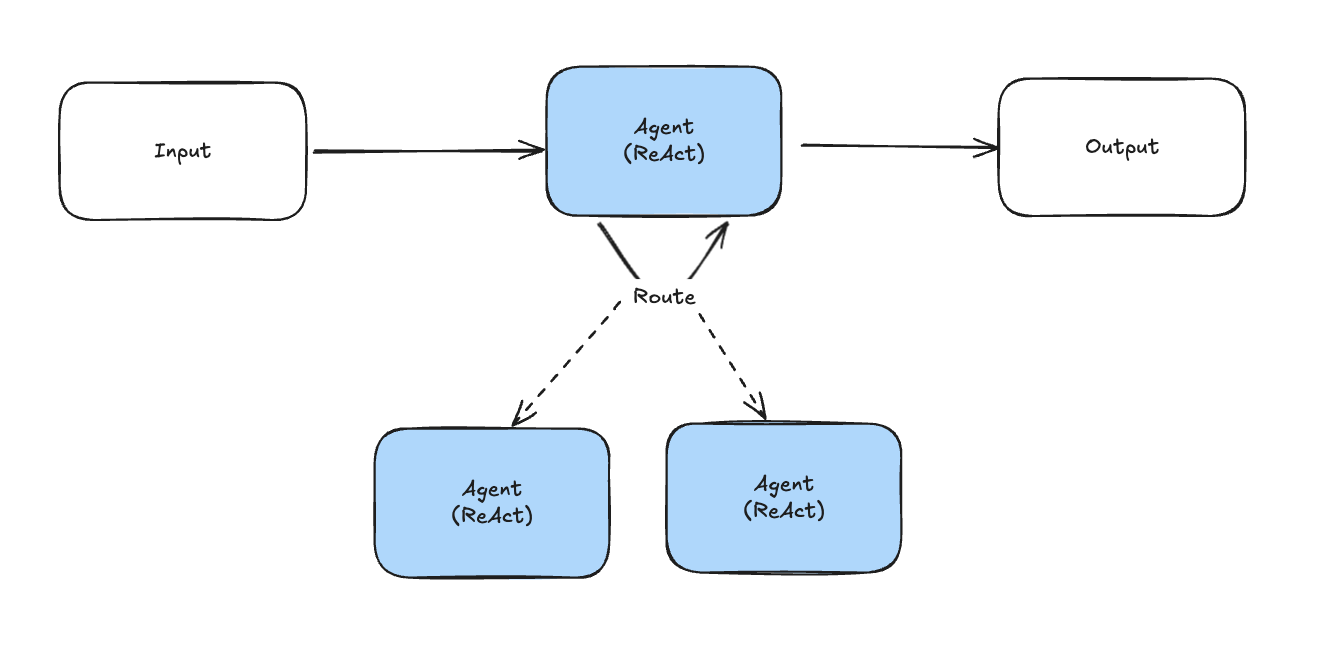
- 상태의 전이도 에이전트에게 맡긴다.
- 중간 에이전트가 다른 에이전트들간의 통신을 필요에 따라 판단하여 제어한다.
- 상태의 전이를 상태 머신을 통해 미리 설계한다.
- 일반적으로, 작업 결과물 생성 에이전트 + 결과물에 대한 검증 에이전트(들) 로 2개 이상의 에이전트로 구성된다.
- 추론 과정을 여러 에이전트가 스스로 계획하기 때문에 생성속도가 느리며, 최악의 경우에는 결과를 내지 못할 수도 있다. (예, 무한루프)
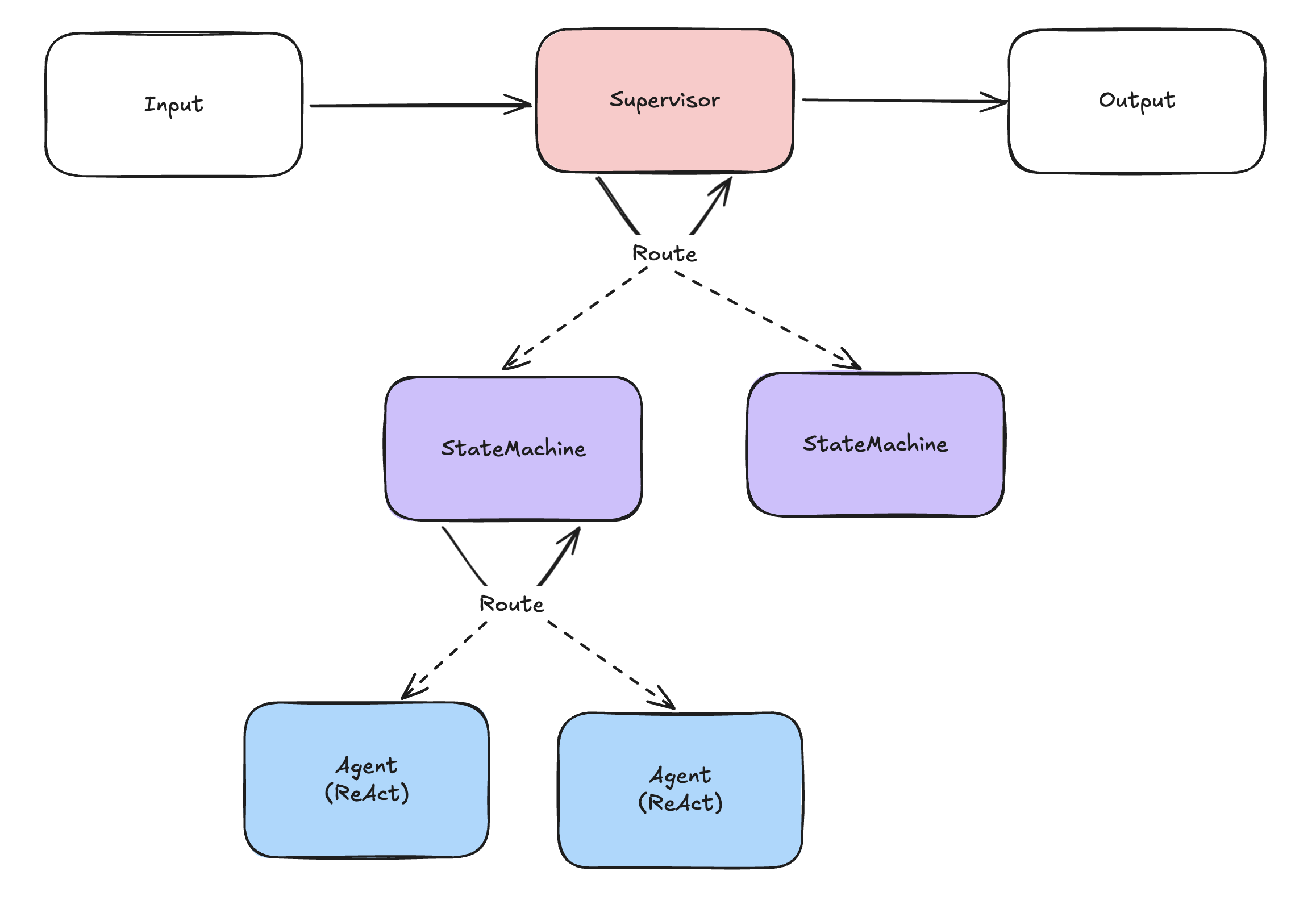
복잡한 멀티 AI 에이전트 시스템 (Complex extended System 2)
- 여러 에이전트를 묶어서 하나의 팀처럼 구성하고, 해당 팀을 이용하여 더 복잡한 문제를 해결하는 시스템이다.
- 매우 복잡한 작업을 처리하는 방식으로 실험적으로만 사용되는 편이다. (e.g. ChatDev1)
AI 에이전트 기반 시스템 설계
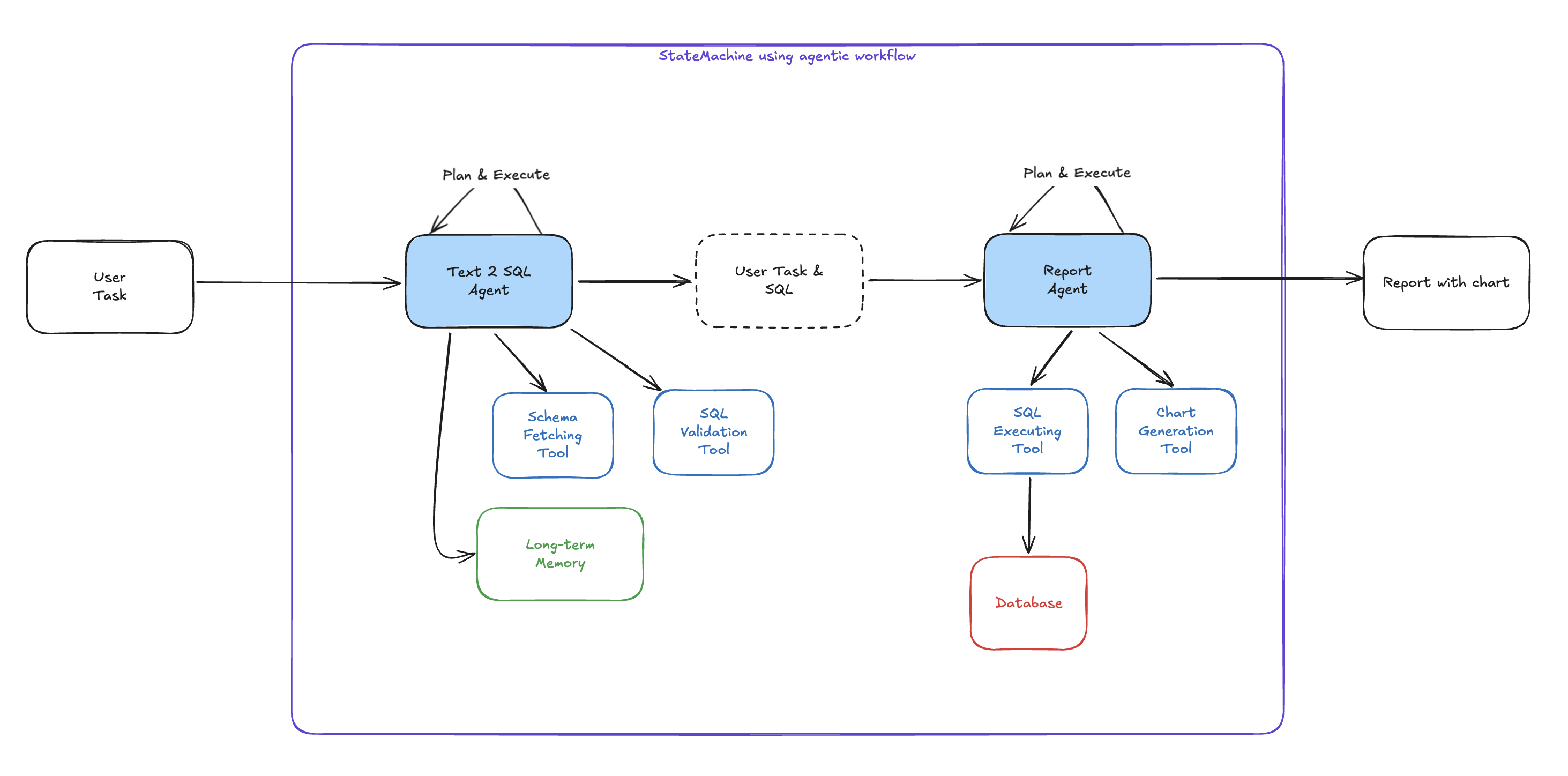
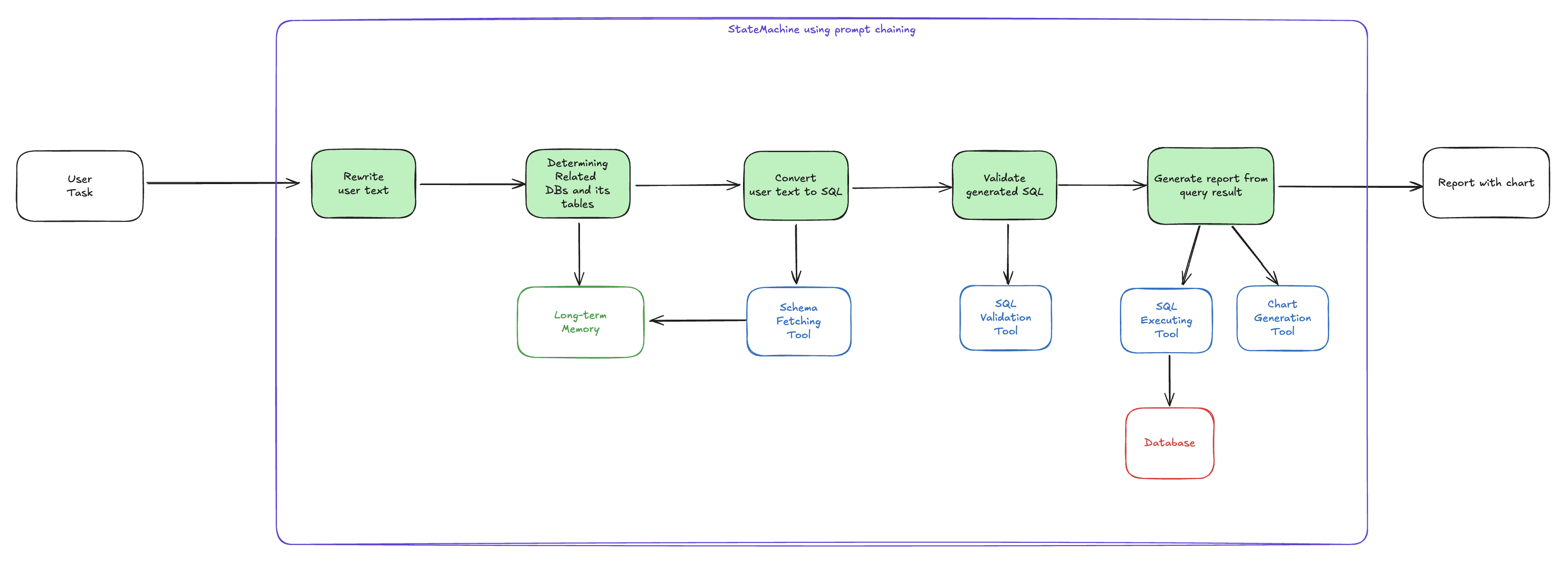
간단한 Text 2 SQL 시스템
아래의 두 그림은 같은 작업을 하는 서로 다른 구현방식이다.
- 사고과정 자체를 에이전트에 맡기고, 필요에 따라 여러 에이전트로 나눠서 구성할 수 있다.
- 전체 흐름을 제어하기 어렵지만, 상대적으로 만들기 쉽다.
- 처리시간 및 비용 최적화와 디버깅이 상대적으로 어렵다.
- 도메인 전문가가 없는 워크로드 (e.g. 리서치) 등의 작업에 도입하는 경우가 많다.
- 프롬프트 체이닝을 아래와 같이 구성하면 하나의 에이전트를 만들 수 있다.
- 전체 흐름을 상태 머신을 통해 직접 설계해야하지만 처리 시간과 비용을 예측하고 최적화 하기 용이하다.
- 흐름 설계가 초기에 일어나야 하며 최적의 흐름을 설계해야 하므로 이미 흐름을 잘 알고 있는 분야(e.g. 자동화) 에 사용되는 경우가 많다.
고려할 내용
트레이싱 및 디버깅
- 각 에이전트에 대한 사고 과정을 직접 지정하거나 전적으로 맡길 수 있다.
- 특정 요청에 대해 원하는 결과가 나오지 않을 경우 아래와 같은 과정으로 디버깅 하게 된다.
- 요청에 대한 유니크한 아이디를 이용하여 해당 요청에 대한 모든 LLM 로그를 확인한다.
- LLM 로그를 통해 어떤 부분에서 잘못된 사고과정을 거쳤는지 파악한다.
- 아래와 같은 방식으로 문제를 고친다.
- 좀 더 정교한 사고를 할 수 있도록 프롬프트를 추가해준다.
- 필요한 외부 데이터를 가져올 수 있도록 RAG 기능을 추가해준다.
- 필요에 따라 새로운 툴을 추가해준다.
요청 시간 및 비용
- 에이전트 기반 시스템은 에이전트의 특성상 요청에 대한 처리시간과 비용을 예측하기 어렵다.
- 따라서 일반적으로 각 요청에 대해 처리시간, LLM 호출 횟수나 처리 토큰 수 등에 상한선을 지정하여 에이전트를 설정하게 된다.
- 이러한 설정값은 위에 설명했듯이, 경험적으로 설정될 수 밖에 없으므로 새로운 에이전트를 만들때는 비용과 리소스에 대한 모니터링이 필수적이다.
동시성 제어
- 복잡한 에이전트는 RAG 나 툴을 이용하여 외부 리소스를 사용하게 된다.
- 일반적으로 이러한 외부 리소스들은 제한된 동시성 (rate limit) 을 제공한다.
- 에이전트 시스템에 여러 작업이 동시에 요청될 경우, 작업에 따라 여러 에이전트가 여러 외부 리소스를 호출하게 되며, 제한된 외부 리소스를 쉽게 고갈 시킬 수 있다.
- 에이전트별 또는 외부 리소스별로 동시성을 제어할 수 있도록 시스템을 구성해야 한다.
비동기 요청 처리
- 위에 설명한 요청 시간에 대한 예측의 어려움과 동시성 제어에 대한 관리를 위해 비동기 요청 처리가 필요하다.
- 특히 복잡한 에이전트 기반 시스템은 요청후 긴 시간동안 사용자가 대기 해야하므로, 사용자 경험 측면에서 일반적인 챗봇형태와 다르게 구성할 필요가 있다.
백오피스
- 위에 소개한 각 단계별로 등장한 모든 요소들의 생명주기를 제어할 수 있는 기능을 제공해야한다.
- 프롬프트의 관리 (생성 / 수정 / 삭제)
- 에이전트의 관리 (생성 / 수정 / 삭제) 및 상태 관리 (실행 / 강제종료)
- 상태머신의 관리 (생성 / 수정 / 삭제)
- 에이전트가 사용하는 리소스 제어 (동시성)
- 에이전트가 사용된 시간 및 비용 계측
마치며
에이전트 시스템을 구현할 때는 또 다른 내용들이 고려되어야 하는데 글에서는 다루지 않았다.
구현시 고려할 내용의 예를 하나만 들면 패키징 단위 가 있을 것이다.
구체적으로는, 하나의 에이전트당 하나의 컨테이너로 빌드해서 배포한다고 할 때, 툴을 같이 묶어서 빌드할 것인지(일반적인 에이전트 프레임워크 방식들), 아니면 툴과 에이전트를 개별로 빌드할 것인지 (아마존 베드락 에이전트가 람다를 이용하서 툴을 호출하는 방식) 이다.
이러한 내용들은 구현하려는 시스템의 특성에 따라 다르게 결정되어야 하므로, 구현 전에 충분한 검토가 필요하다.