Perplexity 는 내부적으로 어떻게 동작할까?
2025년 01월 10일 작성TL;DR
- 코드는 여기1
- Plan and Solve 기반의 Agentic workflow
시작하며
최근 Perplexity 와 유사하게 동작하는 에이전트를 구현할 일이 있어서 퍼플렉시티가 동작하는 방식을 간단히 정리해본다.
Overview
퍼플렉시티는 정확한 정보를 찾는데 목표를 둔 검색엔진으로2, 실행하는 과정을 투명하게 공개하는 UI 를 가지고 있기 때문에, UI 를 자세히 들여다보기만 해도 어떻게 동작하는지 아는 것은 어렵지 않다.
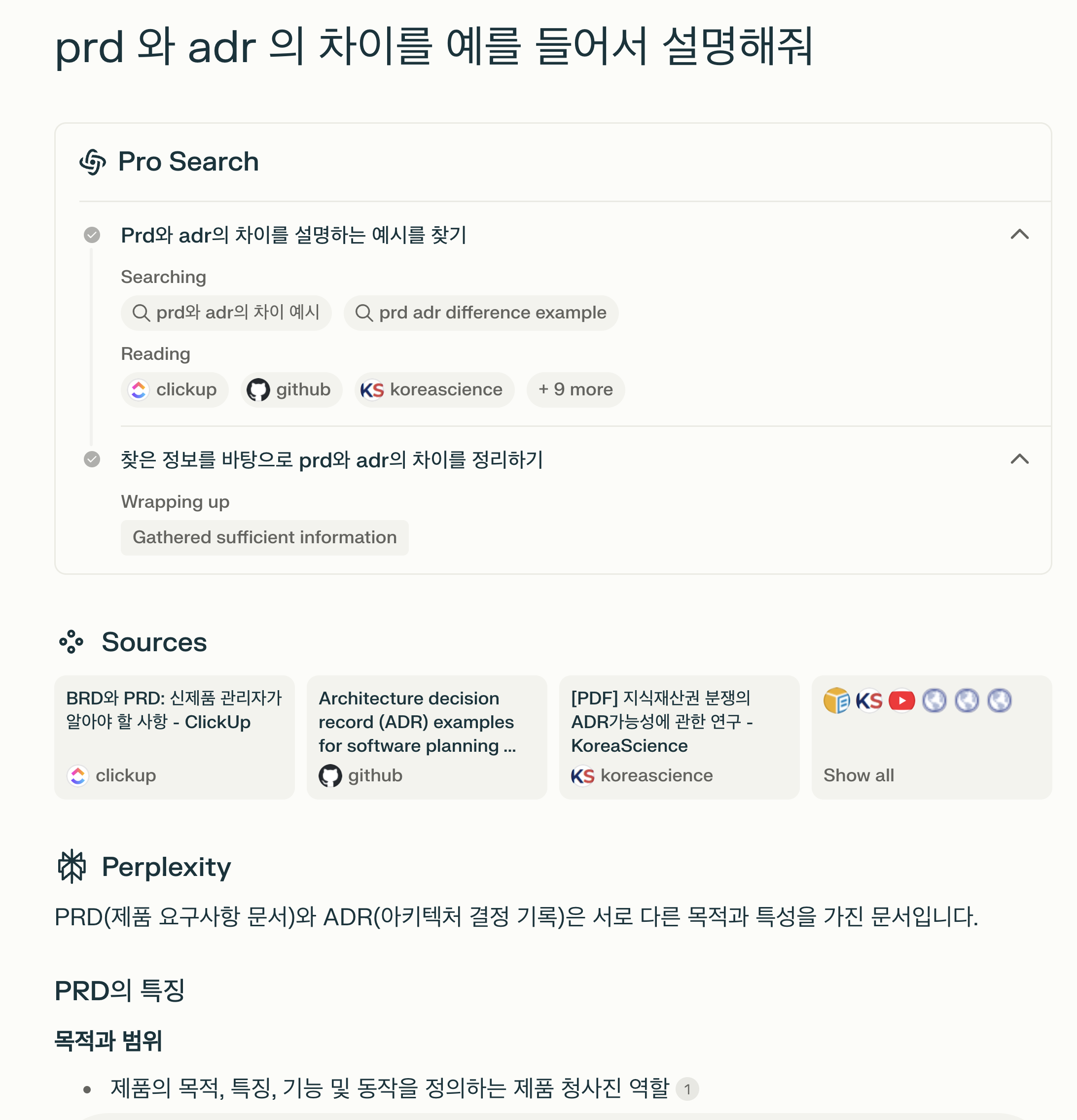
사용자가 검색을 하게 되면
- 먼저 플래닝을 해서 작업을 만든다. (위의 예제에서는 2개의 작업이 있으며, 검색엔진이므로 각 작업은 검색과 검색결과에 대한 정리 작업이 주가 된다.)
- 각 작업을 좀 더 살펴보면, 작업의 목표가 있고(
prd 와 adr 차이를 설명하는 예시를 찾기) 해당 작업을 완료하기 위해 쿼리를 2개 만들어 낸다. (prd 와 adr 의 차이 예시,prd adr difference example) - 각 쿼리에 대한 검색결과로 문서가 12개가 있다는 것도 확인할 수 있다. (Reading section)
- 마지막 작업은 항상 정리(Wrapping up) 으로 끝난다.
결국 여러개의 작업으로 이뤄진 계획을 먼저 세우고, 해당 작업을 순차적으로 실행함으로써 완료되는 직선적인 프로세스를 가지고 있다고 볼 수 있다.
Planning agents
보통 에이전트라고 하면 ReAct 와 같이 스스로 계획을 세우고 완료해나가는 방식을 떠올린다.
해당 방식은 최적의 처리 프로세스가 알려지지 않은 문제를 해결할 때는 효과적이다.(예, 연구, 에세이 쓰기 등) 하지만 o1 을 써보면 알겠지만 얼마나 걸릴지 예측이 불가능하므로(reasoning trajectory 를 예측할 수 없으므로) 대규모 사용자를 처리하는 워크로드에 적용하기에는 적합하지 않다. (쿼리당 비용이 높고 안정성이 낮다.)
반면, 반대 극단에서 모든 것을 개발자가 계획하는 것은 그냥 기존처럼 프로그램을 작성하는 것이라고 볼 수 있다. (쿼리당 비용이 낮지만 안정성이 높다.)
따라서 개발자가 계획흐름 적당히 세우고 해당 흐름 내에서만 자율성을 가지는 형태로 에이전트를 설계하는 방법을 사용하는 것이 안정성과 비용의 균형을 잡는 방법이 될 것이다.
내용을 정리하면 대략 이렇다.3
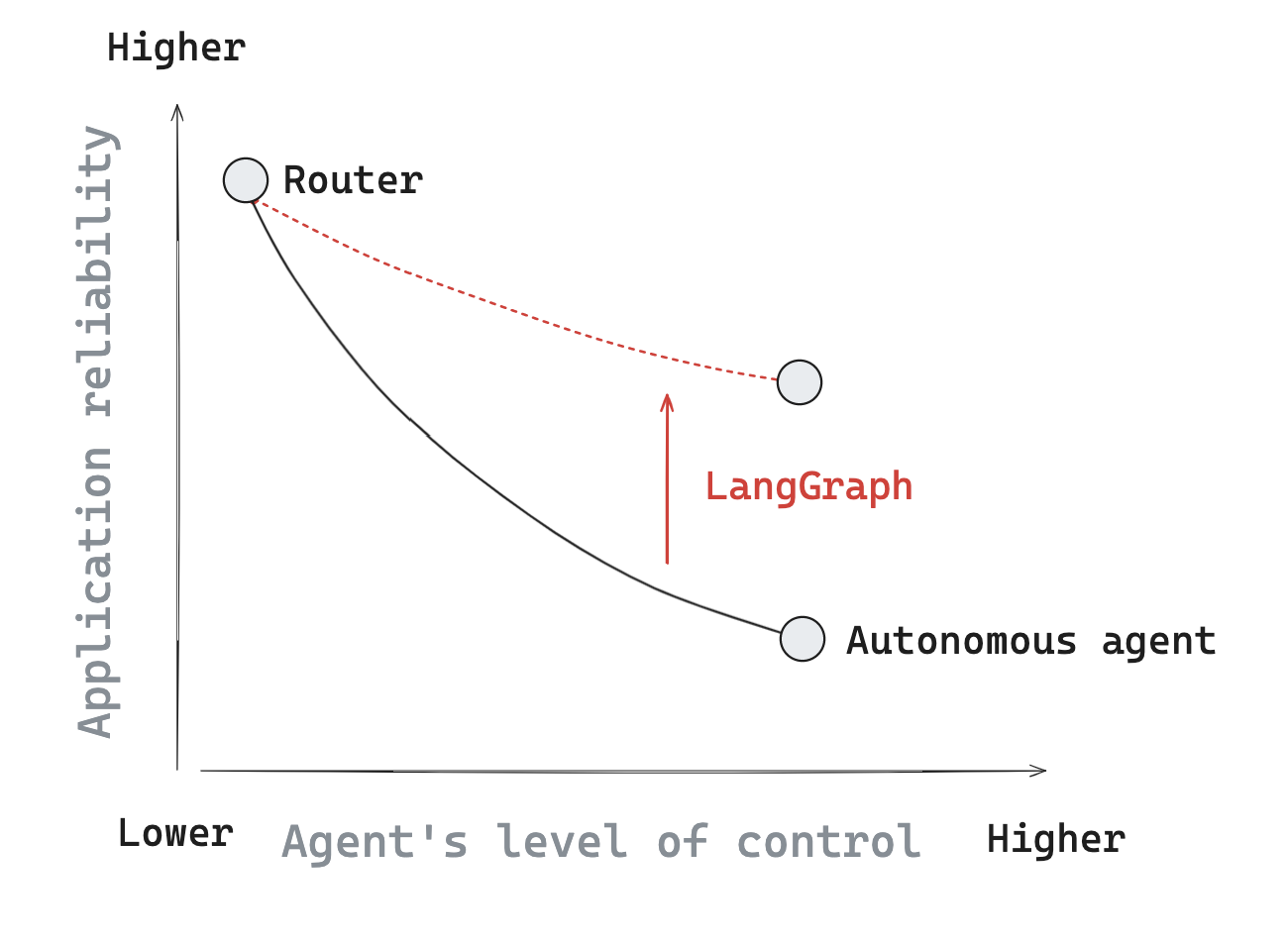
- Plan and Execute 방식이 ReAct 보다 나은 이유는 크게 3가지
- 성능 향상: 계획자가 모든 단계를 명시적으로 계획하고 문제를 세분화하여 성능이 향상된다.
- 더 빠른 실행: 각 하위 작업마다 LLM을 호출할 필요가 없어서 속도가 빠르다.
- 비용 절감: 도메인 특화 LLM 모델을 사용하여 비용을 줄일 수 있다.
그럼 계획을 먼저 세우고 실행하는 방식의 에이전트를 구현하려면 어떻게 하면 좋을까?
세부적으로는 많은 기법들이 있지만 여기서는 LangGraph 에서 잘 정리한 자료 하나만 간단히 소개해본다.4 크게 아래 3개의 방식이 있으며 각각의 특징은 다음과 같다.
Plan and Solve
- 계획을 먼저 세우고 해당 계획에 맞춰서 실행
- 실행결과를 평가했을 때 요청이 완료되지 않았다면 재계획을 통해 다시 계획을 세우고 반복한다.
- Perplexity 가 사용하는 방식과 가장 유사하다. (재계획 없음)
ReWOO
- ReAct 의 Though-Action-Observation 루프에서 Observation 을 제외하고 액션을 기반으로 계획을 먼저 생성한 뒤에, 생성된 계획만 그대로 실행한다.
- PS 와 다른 점은 ReWOO 에서는 어떤 도구와 파라미터를 쓸지 까지 미리 계획한다. (PS 에서 플래너는 계획만 세우고 도구와 파라미터는 Single Task Agent 가 판단한다.)
LLM Compiler
- 플래너가 계획을 세울 때 DAG 형태로 구성하여 병렬로 실행할 수 있는 작업과 순차로 해야하는 작업을 구분할 수 있게 한다.
- 계획을 모두 실행후 작업이 미완료되었다면 재계획을 한다. (PS 와 동일)
- 전체적으로 PS 와 비슷하지만 플래너가 각 세부작업 간의 의존성을 파악해서 계획을 세우기 때문에 플래너가 매우 똑똑해야 한다.
- LlamaIndex 의 StructuredPlanner5 가 해당 방식으로 구현되어 있다.
Data flow
결국 종합해보면 퍼플렉시티는 아래와 같은 형태로 구성되어 있을 것으로 예상해볼 수 있다.
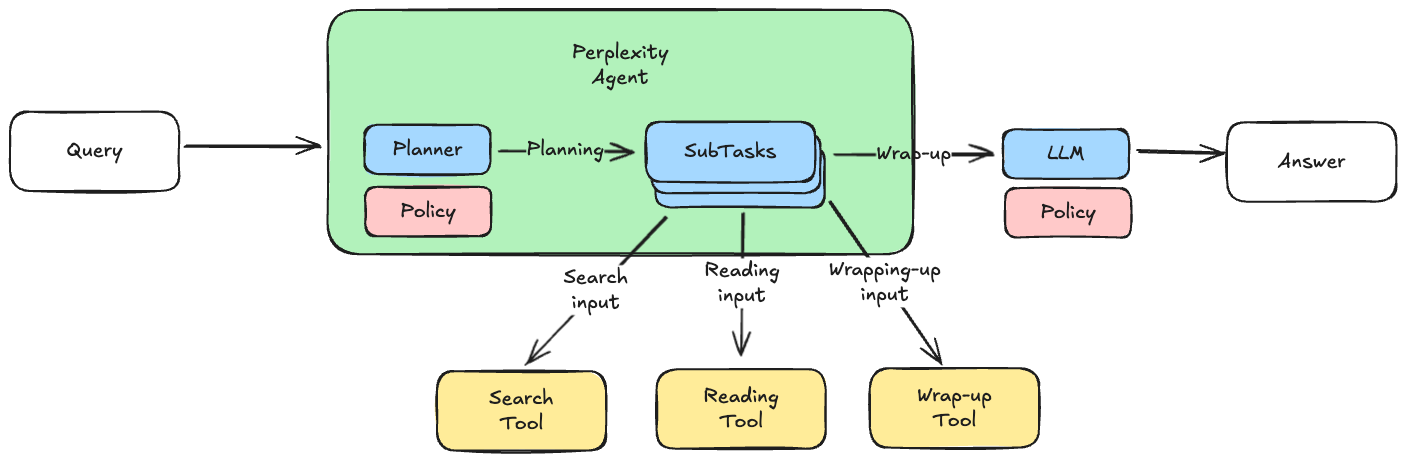
- 사용자가 쿼리를 요청하면
- 플래너가 서브태스크들을 만들어낸다.
- 각 태스크는 LLM 의 도구호출 기능을 통해 적절하게 데이터를 확보한다. (검색, 요약 등)
- 정리된 결과를 바탕으로 답변을 생성해낸다.
Data search
가장 중요한 도구인 검색 부분을 어떻게 처리할 지 고민하다보면 몇가지 옵션을 찾을 수 있다.
- SerpAPI - LLM 친화적인 구글검색
- TavilyAPI - LLM 친화적인 검색엔진
- 직접 LLM 친화적인 검색엔진 구현
SerpAPI 의 경우 문서의 링크들을 주지만 해당 링크의 내용은 직접 요청해서 받아야 하기 때문에 Reading 도구를 추가로 호출해줘야한다.
반면 TavilyAPI 는 문서의 링크와 함께 해당 문서의 내용을 요약해서 주기 때문에 Reading 도구가 필요하지 않다.
하지만 위의 두 방법 모두 서드파티 API 를 호출하기 때문에 응답속도가 안정적이지 않고 추가비용이 많이 발생한다.
따라서 프로덕션에서는 LLM 친화적인 크롤러를 구현할 필요가 있으며, 실제로 퍼플렉시티도 크롤러를 통해서 데이터를 내부에 쌓아두고 RAG 검색을 하는 것으로 보인다. (속도측면에서)
마치며
위에 소개한 방식으로 구현해보면 적절하게 잘 동작하는 것을 확인할 수 있다. 하지만 위에 소개한 구조는 논리적으로 잘 분리가 되어 있지만 효율적이지는 않다.
따라서 위의 모듈들을 적절하게 통합하고, 결과들을 최적화 하고(rerank 등), 프롬프트를 조정하는 등의 작업을 진행하면 퍼플렉시티와 유사한 같은 속도를 낼 수 있다.