Claude 로 DOM 구조에 자유로운 웹 스크레이핑 기능을 만들어보기 (Firecrawl clone)
2025년 01월 11일 작성TL;DR
- 코드는 여기1
- 웹 페이지의 구조와 무관하게 데이터를 획득할 수 있는 유니버설 솔루션.
- 하지만 오래된 한국 사이트들은 웹 표준을 무시하는 경우가 많다. (특히 커뮤니티들)
시작하며
거의 10년전 스타트업에서 크롤러를 관리한 적이 있다. (메인으로 유지보수하는건 다른 팀원이었지만)
지정된 도메인 몇개를 돌아다니는 크롤러였지만, 여튼 크롤러 특성상 DOM 에 변동이 생기면 데이터를 가져올 수 없기 때문에 상시 모니터링하다가 변동이 생기면 다시 DOM 분석을 해서 코드를 수정하고 하는 작업을 하곤 했었다.
그리고 최근에 웹 스크레이퍼를 만들일이 있어서 찾아봤는데 LLM 덕분에 몇가지 새로운 서비스들이 나와있었고, 꽤 재미있어보였다.
본 글에서는 해당 서비스들을 짧게 살펴보고 그 중에 가장 쓸만해보이는 Firecrawl 의 웹 스크레이핑 기능만 Claude 로 구현해본다.
웹 스크레이퍼와 크롤러는 엄연히 다른 개념이지만, 타이핑을 줄이기 위해 둘다 그냥 크롤러라고 부르겠다.
크롤러 특징
나도 최근에 Encbird2 를 만들어보면서 영어 문장이나 표현에 대한 크롤러를 만들어보려고 했는데 LLM 으로 데이터를 생성하는 것이 모든 면에서 더 나은거 같아서, 크롤러로 각 사이트 데이터를 긁어오는 대신 LLM 으로 데이터를 생성하는 방향으로 바꿨다.
여튼 크롤러를 관리해본 입장에서는 데이터 확보에서 가장 마지막으로 하고 싶은 것이 크롤러 만들기일 정도로, 유지보수 측면에서 손이 많이 가는 것이 크롤러일 것이다.
크롤러를 사용하는 경우는 크게 아래 2가지라고 보면 될 것이다.
- 페이지의 지정된 부분만 가져오는 경우
- 페이지 전체의 텍스트를 가져오는 경우
지정된 부분만 가져오는 경우 는 일반적으로 쇼핑몰 페이지에서 각 상품의 상세정보를 가져올 수 있는 상세페이지 링크를 추출할 때 많이 사용한다. 주로 DOM 을 xpath 나 selector 를 이용해서 파싱한다.
개인적으로 페이지의 모든 링크를 가져와서 도메인만 필터링 한 뒤에 diffscore 기반 KNN 으로 묶는 방식도 예전에는 종종 썼지만 (비슷한 형태의 링크들로 묶었을때 가장 많은 숫자의 링크가 가장 의미있는 데이터일 확률이 높다는 가정) 데이터의 리콜이 중요하면 목록의 마지막 페이지 데이터 때문에 DOM 파싱을 해야한다.
전체 텍스트를 가져오는 경우 는 최근 RAG 때문에 많이 사용하게 되는데, 상세 페이지로 이동한 뒤에 해당 페이지의 전체 내용을 요약하거나 혹은 텍스트 전체를 그냥 벡터데이터베이스에 임베딩해서 넣고 싶을 때 많이 사용한다. 대부분 라이브러리에서 전체 텍스트 추출하는 함수가 있기 때문에 따로 구현할 필요는 없다.
종합하면, 지정된 부분만 추출하는 기능은 대부분의 시나리오에서 반드시 필요하며, 이후 전체 텍스트를 가져오든 다시 한번 지정된 부분만 가져오든지 해야한다.
그리고 지정된 부분만 추출하는 코드는 대상 사이트가 DOM 구조를 바꾸면 반드시 망가지기 때문에 알람을 설정해두고 맞춰서 유지보수를 해야한다.
LLM 을 이용한 크롤러들
요즘 개발할 때 많이 사용하는 Cursor, Windsurf, V0 나 Bolt 등을 써보면 알 수 있지만, 대형 LLM 은 마크업을 잘 이해하고 생성도 잘 한다.
이러한 LLM 의 특성을 활용하여 위에서 말한 지정된 부분만 추출하는 툴들도 많이 있는데 크게 2가지 방향이 있다.
- LLM 에게 마크업을 주고 파싱해달라고 한다.
- LMM 에게 웹 페이지 스크린샷을 주고 파싱해달라고 한다.
LLM이 마크업을 파싱 하는 방식은, 가져오고 싶은 데이터를 자연어로 설명하고 페이지 주소를 주면 적절히 읽어서 필요한 값만 추출해준다. 대표적인 툴은 FireCrawl3 이다.
LMM이 이미지를 파싱 하는 방식은, 가져오고 싶은 데이터를 자연어로 설명하고 Selenium 같은 브라우저 에뮬레이터로 스크린샷을 만들어서 주면 이미지에서 값을 추출해준다. 대표적인 툴은 AgentQL1 이다.
두 방식 다 나름의 장점이 있기 때문에 용도에 맞게 쓰면 된다.
다만 대규모 대상으로의 스케일링을 고려하면 LMM 파싱방식은 가용하지 않을 수 있다. AgentQL 은 현재 두가지를 다 사용하고 있기 때문에 (이미지 + 마크업) 처리당 비용이 더 많이 들어간다. (예전에는 스크린샷으로만 파싱해서 정확도가 매우 낮은편이었다고 알고있다.)
ClaudeCrawl scraper
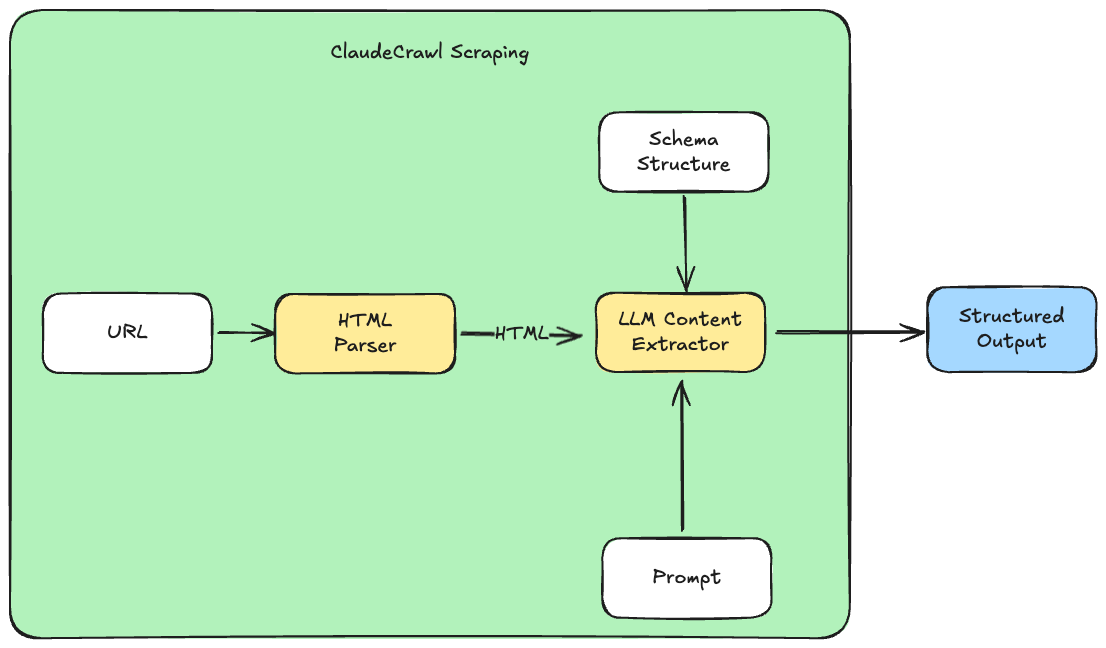
FireCrawl 의 스크레이핑 프로세스는 대략 아래처럼 동작한다.
- URL 주소와 자연어 쿼리를 입력 받는다.
- 페이지의 HTML 을 LLM 에 전달하여 자연어 쿼리에 대한 컨텐츠를 추출한다.
- 자연어 쿼리(프롬프트)를 통해 쉽게 임의의 정보를 지정해서 크롤링 할 수 있다.
해당 방식을 그림으로 대략 그려보면 아래와 같다.
코드1 는 크게 어려운 내용은 없고 일반적인 크롤러와 같다.
코드에서는 Playwright 라이브러리를 통해 브라우저 에뮬레이터를 사용하고 있는데, 최근에는 React, Vue 등을 이용한 CSR 사이트들이 많아져서 해당 사이트의 정보를 로드하려면 정적인 파싱으로는 값을 가져올 수 없다. 따라서 일반적인 크롤러도 대부분 브라우저 에뮬레이터를 써서 마크업을 가져와야 한다.
또 한가지 고려할 점은 LLM 은 입력 컨텍스트 크기가 커질 수록 시간과 비용이 많이 들어간다는 점이다. 따라서 불필요한 html 을 최대한 제거해줘서 (예, 스타일에 해당하는 css 를 모두 제거, 스타일을 위한 wrapper tag 제거 등) 토큰 크기를 줄여주는 것이 좋다.
데모설명
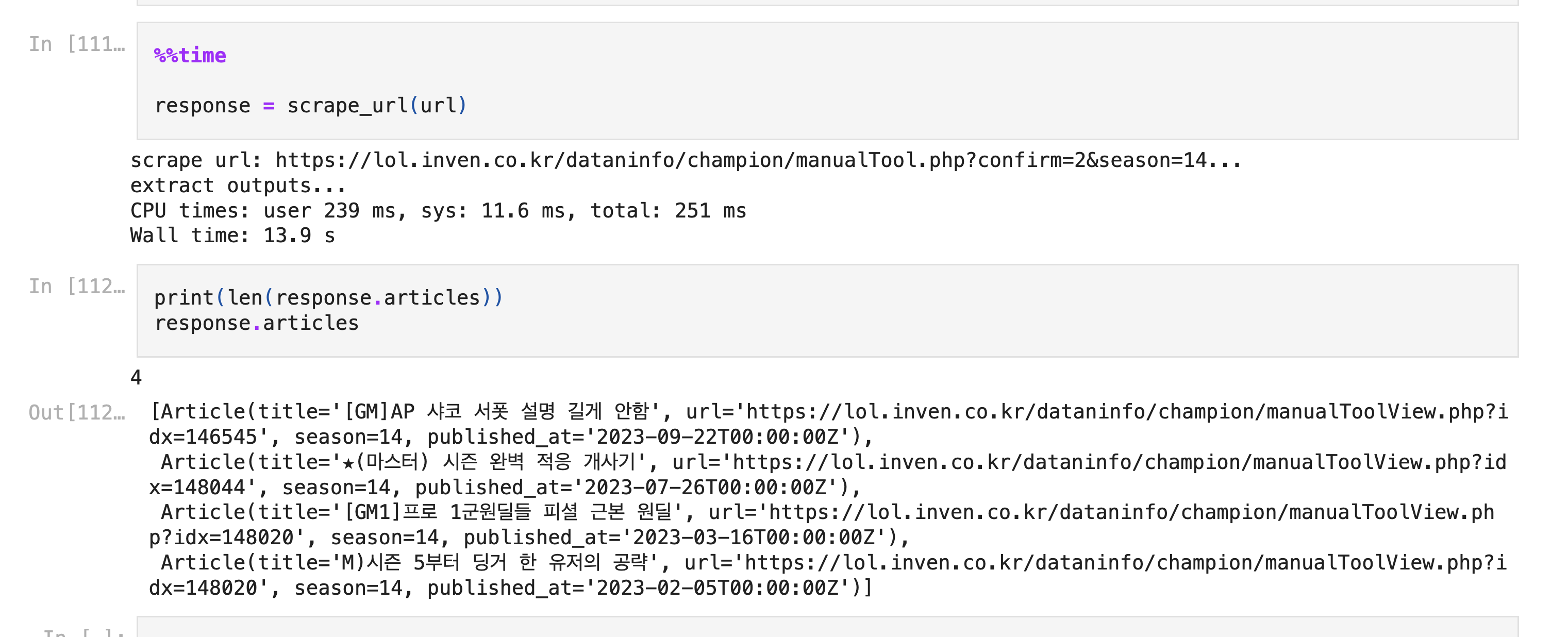
코드1상에는 롤 인벤에서 시즌 14 챔피언 공략을 가져오는 예제로 설정되어 있고, 이 예제에서 FireCrawl 을 실행해보면 제대로 못가져오지만 ClaudeCrawl 은 원하는 데이터를 잘 가져오는 것을 확인할 수 있다.
인벤 같은 국내 커뮤니티 사이트들은 특히 엄청 많은 배너들과 링크들이 배치되어 있기 때문에 불필요한 태그를 잘 제거해주는 것이 성능상 중요하다.
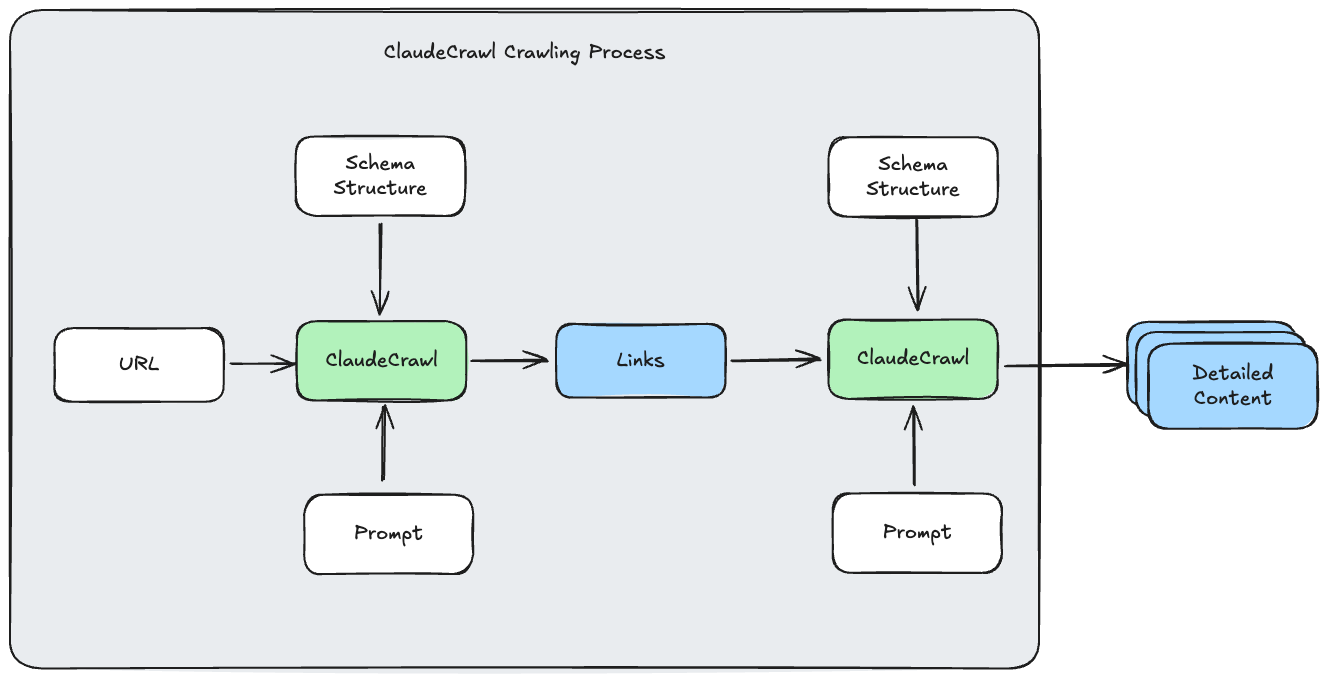
예제에는 없지만 아래와 같이 목록을 가져와서 상세페이지의 데이터를 가져오는 것도 코드 수정없이 입력 인스트럭션만 조정해도 잘 되는 것을 확인해볼 수 있었다.
스케일링
해당 기능을 프로덕션에 적용할 때 가장 문제가 될 것으로 생각되는 것은 스케일링이다.
특히 크롤러 특성상 같은 페이지를 주기적으로 방문하여 값을 계속 가져와야 하는데, 관리해야하는 대상이 늘어나면 시스템 비용이 계속해서 늘어난다. 고전적인 크롤러는 서버컴퓨팅 비용을 (그마저도 IO 비용이 대부분인) 제외하면 비용이 거의 들지 않는 것에 비하면 비용의 부담이 훨씬 커진다.
최근의 에이전트 기반 코드 생성기를 써보면 코드를 잘 작성하는 것을 경험할 수 있다. 이 방식을 활용하면 반복적인 방문에 의한 비용 문제를 어느정도 해결할 수 있다.
즉, HTML 을 LLM 이 직접 파싱하는 대신, LLM 이 HTML 을 파싱하는 코드를 작성하고 해당 코드로 파싱하는 방식을 사용하는 것이다.
이렇게 처음 코드를 생성하기 위해서는 AgentQL 방식으로 LMM 모델을 이용하는 것이 좋을 수도 있다. 확실한 데이터를 먼저 추출해서 해당 데이터가 나올 때까지 코드 생성을 스스로 조정해 나가도록 에이전트를 설계하는 것이다.
마치며
결국 LLM 기반 프로젝트는 이게 될까? 에서 이게 되네 그리고 근데 비용을 어떻게 줄이지? 으로의 여정이다.
결과물이 아무리 좋아도 최종적으로 ROI 때문에 프로덕션에 갈수가 없는 경우를 종종 보는데, 비용 때문에 작은 모델을 사용하자니 모델 스케일링 법칙에 의해서 아직은 일정 이하 크기의 모델은 쓸 수가 없고, 직접 호스팅 하자니 ML 인력이 필요해지기 때문이다.
따라서 최근의 LLM 프로젝트는 무조건 ROI 를 먼저 계산해보고 진행하는 것이 좋다. 다만 비용이나 속도가 개선되는 주기가 점차 빨라지고 있기때문에 (단순 토큰당 비용감소 뿐만 아니라 프롬프트 캐시 등의 새 기능을 포함) 그렇다고 너무 단기간의 손익을 따지는 것보다는 이러한 기술의 개선으로 인한 비용감소도 어느정도 고려하면서 계산해야 한다.