간단히 설명한 피지컬(Physical) AI
2026년 01월 02일 작성TL;DR
- 피지컬 AI 란 AI 를 이용해서 모터를 제어하는 방법
- AI 는 Foundation Model 기반과 IL + RL 기반의 방식으로 나눌 수 있음
- 모터제어는 Diffusion 방식이 현재 대세
- 결국은 데이터 싸움
시작하며
2024년 초에 고객사와 LLM 을 이용해서 로봇을 제어하는 프로젝트를 진행했다.
나는 로봇에 대한 지식이 전무했고, 고객은 AI 에 대한 지식이 전무했으며, 둘다 VLA(Vision Language Action) 에 대한 지식은 전무했기 때문에 초반에 리서치를 많이 하게 되었다.
당시에도 ChatGPT 덕분에 논문 읽는 것은 수월해져서, RT-1, RT-2, RT-X, SayCan, L2R, VoxPoser, Eureka, Diffusion Policy 등 일단 집히는 대로 읽었고, 결국 내린 결론은 LLM 들과는 비교도 안되게 로보틱스 데이터의 중요성이 크다는 것 이었다. (처음 고객과의 논의 시발점이 었던 Covariant 대표도 원래 OpenAI 의 소속이었으나 로봇데이터를 쌓기 위해서 독립회사를 차림)
따라서 데이터를 쉽게 쌓을 수 있는 환경이 먼저 필요하다는 생각을 하게 되었다. 고객의 상황상 이를 위해서는 시뮬레이션 환경이 좋겠다고 생각했고, 다양한 작업에 대해서 로봇코드를 자동으로 만들기 위해서는 LLM 이 제격이었다.
비슷한 아이디어 (로봇 + 시뮬레이션 + LLM 조합)의 논문들을 참고해서, Vision Model 들과 LLM 만으로 시뮬레이션 상에서 로봇을 매니퓰레이션을 하는 데모를 만들었다.
위의 영상을 좀 더 발전시켜 3단 찬장에서 임의의 캔을 집어서 내려주는, 간단하다면 간단한 매니퓰레이션 태스크까지 발전시켰고, 시뮬레이션 상에서는 원하는 작업들을 80% 남짓의 성공률로 처리할 수 있었다.
이후 고객의 노력으로 실제 로봇팔에도 같은 시스템을 배포하여 리인벤트 및 내부 행사에서도 데모를 할 수 있었다.
그 뒤로 완전히 손 놓고 있다가, 최근 피지컬 AI 에 대한 관심이 다시 생겨나고 있어서 몇가지 찾아보게되었다.
2년이 지난 지금에도 nvidia 의(아마도 피지컬 AI 의) 초기 방향성과 방법론이 거의 그대로 유지되고 있는 것 같았다. 그리고 지난 기간동안 짧게 공부했던 내용을 정리해두는 것이 앞으로 더 공부해나가는데 도움이 될 수도 있겠다는 생각이 들었다.
따라서 본 글에서는 피지컬 AI 를 시작하는 입장에서 알아두면 좋은 내용들을 정리하고, 공부하는 순서도 간단히 정리해본다.
피지컬 AI
피지컬 AI 는 쉽게 말해서 AI 를 통해서 모터를 제어하는 방법이다.
AI 로 모터를 제어하는 방식은 크게, 아래의 3가지 방식이 있다고 보면 된다:
- IL + RL 방식 (유니트리 G1 locomotion 등)
- Foundation Model 기반의 방식 (GR00T N1 등)
- 둘을 적절히 합쳐서 쓰는 방식 (π₀, RT-X 등)
내가 처음 피지컬 AI 라는 용어를 접했던건 Jim Fan 의 TED 영상1이었던거 같다. 해당 영상을 먼저 보고, 같은 주제로 2년 뒤에 발표한 아래의 영상을 보면 좀 더 잘 이해할 수 있는 것 같다.
개인적으로는 향후 피지컬 AI 를 공부할 때 nvidia omniverse 의 서비스들을 알고 있는 것이 매우 유리하다고 생각한다. 위의 영상을 통해, 피지컬 AI 개발과정에서 nvidia 서비스들의 역할에 대한 기본적인 이해를 가져가면 좋을 것 같다.
필수 로보틱스 지식
피지컬 AI 에서는 로봇제어시 대부분 엔드-이펙터(End-Effector) 라고 부르는 마지막단 관절을 기준으로 (x, y, z, roll, pitch, yaw, gripper) 로 구성된 7 DoF (Degree of Freedom) 표기를 많이 사용한다.
따라서 (x, y, z) 를 결정하는 좌표계 개념과, (roll, pitch, yaw) 를 결정하는 축 및 쿼터니언이라고 부르는 축의 회전 개념 정도를 이해하고 있으면 된다.
약간 더 나가면 (x, y, z) 로 어떻게 로봇의 각 관절 (joint angles) 을 조정하는지를 설명해주는 정기구학과, 역기구학의 기본 개념도 알아두면 좋다.
앞으로 피지컬 AI 관련된 하드웨어 제조사들이 더 많이 생겨나게 되면서, 개발자들이 로봇제어보다 비즈니스 로직에 더 집중할 수 있도록 MPC (Model Predictive Control) 나 충돌감지등의 다양한 기능들이 내장된 로봇들이 나올것으로 예상된다.
따라서 로봇개발자가 아닌 일반 개발자 입장에서는, 시작할 때부터 로보틱스의 방대한 지식을 다 공부하면 답이 없기 때문에, 위에 설명한 기본 개념들만 이해하고 있어도 코드를 읽고 로봇을 돌려보는데는 충분할 것 같다.
Imitation Learning, Reinforcement Learning
피지컬 AI 에서 로봇을 제어하는 방식은 IL → IL+RL → Foundation Model 순서로 발전해왔다. 각 방식의 한계를 극복하기 위해 다음 방식이 등장했다고 보면 된다.
IL (모방학습)
모방학습(Imitation Learning)은 전문가가 시연하면 모델은 그 시연을 최대한 따라하게끔 학습된다. 요즘 피지컬 AI 를 처음 시작하는 사람들이 LeRobot 으로 ACT(Action Chunking Transformer) 를 학습시켜보는 경우가 많은데, ACT 가 바로 IL 용으로 설계된 대표적인 모델이다.
IL 의 장점은 데모 데이터만 있으면 빠르게 “일단 되는” 수준까지 만들 수 있다는 것이다. 하지만 IL 만으로는 한계가 뚜렷하다. IL 정책은 데모 분포를 따라가기 때문에, 데모에서 조금만 벗어나면 (물체 위치가 다르거나, 조명이 바뀌거나, 그립이 실패하는 등) 대응을 못한다.
IL + RL
IL 의 한계를 극복하기 위해 RL(강화학습)을 결합한다. 강화학습은 보상함수의 값을 최대화하도록 무한히 try-and-error 하는 방식이다.
실무에서 흔한 방식은 IL 로 먼저 “일단 되게 만들고(warm start)”, RL 로 “성능과 견고함을 올리는(fine-tune)” 것이다. IL 이 기본 동작을 학습하게 해서 이상한 동작을 하지 않도록 하고, RL 이 실수했을 때 회복하는 능력과 다양한 상황에 대한 견고함을 더해준다.
하지만 IL+RL 방식도 한계가 있다. 작업마다 데모를 새로 수집하고, 보상함수를 새로 설계하고, 학습을 새로 해야 한다. 즉, 일반화(generalization)가 안 된다.
Foundation Model (VLA)
이 한계를 극복하기 위해 등장한 것이 VLA(Vision Language Action) 같은 Foundation Model 기반 방식이다. LLM 이 다양한 텍스트 작업을 하나의 모델로 처리하듯이, VLA 는 다양한 로봇 작업을 하나의 모델로 처리하려고 한다.
Foundation Model 방식의 핵심은 대규모 데이터로 사전학습된 모델이 새로운 작업에도 적응할 수 있다는 것이다. 작업마다 처음부터 학습하는 것이 아니라, 언어 명령어로 원하는 작업을 지시하면 모델이 알아서 수행한다.
물론 현실에서는 Foundation Model 만으로 모든 것이 해결되지 않기 때문에, π₀ 나 RT-X 처럼 Foundation Model 과 IL+RL 을 적절히 결합해서 사용하는 방식이 많다.
해당 영상을 보면 구글 딥마인드에서 어떤 과정을 거쳐서 RT-X 라는 최신 모델까지 도달했는지 눈물겨운 여정을 살펴볼 수 있다.
데이터 증강
피지컬 AI 의 가장 큰 난제는 데이터 부족이다. LLM 은 인터넷에서 텍스트를 긁어올 수 있지만, 로봇 제어 데이터는 그렇게 얻을 수 없다. 사람이 VR 기기를 쓰고 로봇을 원격 조종(Teleoperation)하는 방식은 고품질 데이터를 제공하지만 확장이 불가능하다.
이 문제를 해결하기 위해 시뮬레이션과 생성형 AI 를 활용한 데이터 증강 방식이 발전하고 있다.
- 시뮬레이션 1.0 (디지털 트윈): Isaac Sim 같은 시뮬레이터에서 대규모 병렬 시뮬레이션과 도메인 랜덤화를 통해 데이터를 생성한다. 하지만 이 방식도 시간이 오래 걸린다.
- 시뮬레이션 2.0 (디지털 커즌): NVIDIA 는 생성형 AI 를 활용해 데이터를 증강하는 방식을 사용한다. Cosmos Transfer 로 환경을 변형하고, Cosmos Predict 로 미래 상태를 예측하고, GR00T Dreams 로 비디오 월드 모델을 신경 시뮬레이터로 사용한다.
특히 GR00T-Mimic 은 소수의 시연 데이터(10개 정도)를 입력받아 수천 개의 새로운 궤적을 자동으로 생성한다. 물체 위치를 무작위로 바꾸거나 동작을 변형해서 데이터를 뻥튀기하는 방식이다. 사람이 10번만 시연해도 로봇이 수천 번 연습한 효과를 낼 수 있다.
비디오 기반 월드 모델은 수십억 개의 인터넷 영상을 통해 물리적 현상을 학습하므로, 복잡한 물리 법칙을 일일이 프로그래밍할 필요가 없다는 장점이 있다.
Transformer and Diffusion
피지컬 AI 모델들을 대략 이해하려면 트랜스포머와 디퓨전 방식에 대해서 어느정도 이해하고 있어야 한다.
Transformer
최근에는 다양한 비전 모델들 아이디어들이 CNN 에서 결국 DiT 로 전환되었듯이, 피지컬 AI 도 트랜스포머 기반의 모델이 대세가 되고 있다.
우리가 흔히 접하는 트랜스포머인 LLM 을 생각해보면, 여러 토큰을 입력받아서 다음 토큰 하나를 출력하는 방식으로 동작한다.
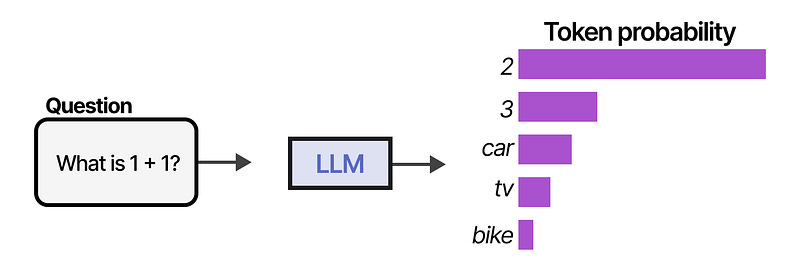
이미지를 입력받는 경우에도 사실 똑같은데 이미지를 패치(patch) 라는 단위로 잘라서 토큰으로 변환한 뒤 입력하는 것 외에는 동일하다.
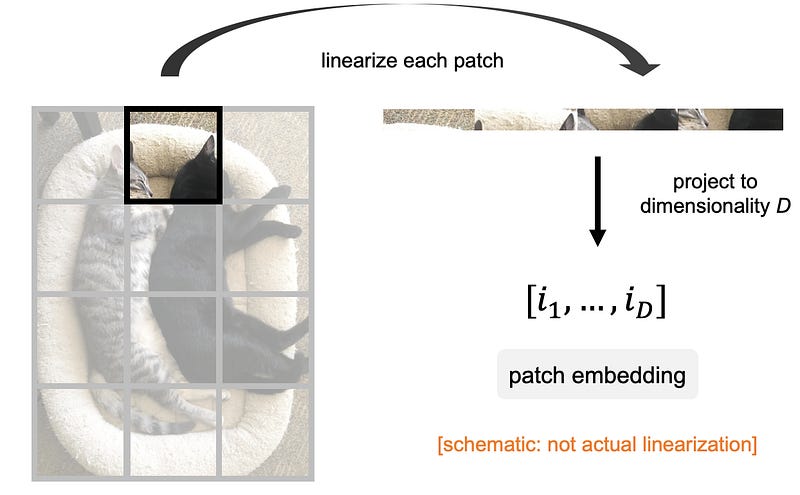
즉, 모든 트랜스포머는 기본적으로 토큰들을 입력하고 다음 토큰을 출력하는 방식으로 동작한다.
VLA (Vision Language Action) 모델들도 트랜스포머 기반의 모델이므로, 토큰을 입력받아서 토큰을 출력한다.
이때 입력은 이미지, 텍스트, 현재 로봇의 상태 를 각각 토큰으로 변환해서 입력하고, 출력은 모터 제어 명령어를 토큰으로 변환해서 출력한다. 토큰입력 -> 다음 토큰 출력 형태는 변함이 없다.
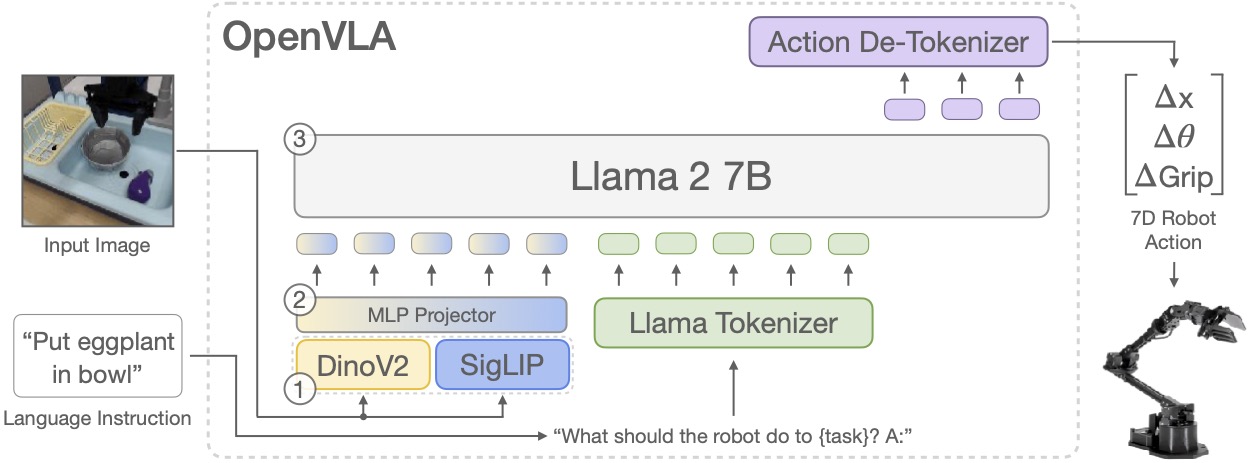
좀 더 의미를 살려서 설명해보자면, 사람처럼 현재 프레임의 상태정보와 달성하고 싶은 목표를 입력받아서, 목표를 달성하기 위해 다음 프레임에 어떤 액션을 취해야 하는지를 출력하는 모델로 학습한다고 볼 수 있다. 이렇게 동작하는 대표적인 예가 OpenVLA 모델이다.
다만, 이렇게 프레임단위로 액션을 출력하면 현재의 상태만 입력받기 때문에 현재 이동중인 속도등을 알 수 없으므로 자연스럽게 보이지 않고, 덜덜 떨리는 식으로 동작하게 된다.
Diffusion Model
이런 부분을 보완하기 위해서 나온 것이 이미지, 영상 생성 모델에서 많이 사용하는 디퓨전 방식이다. 디퓨전 방식은 입력에 노이즈를 주입하고 노이즈를 예측해서 제거하는 출력을 생성하도록 학습한다. (즉, 노이즈 예측 학습)

한가지 생각해볼점은 트랜스포머에서 원래 입력은 아까 트랜스포머에서 이미지는 패치단위로 잘라져 있다고 했다. 디퓨전은 노이즈를 예측해서 제거하는 모델이므로 패치단위로 예측하는 것이 아니다. 트랜스포머에서 디퓨전을 적용해서 (DiT) 이미지를 생성한다는 것은, 한 패치씩 순서대로 생성하는 것이 아니라, 이미지 크기만큼의 토큰을 미리 준비해두고 모든 토큰의 값을 노이즈를 제거해서 한번에 예측하는 것이라고 보면 된다.
Diffusion Policy, GR00T, π₀ 등은 이 DiT 방식을 응용해서 프레임 단위로 액션을 예측하지 않고, 현재 프레임에서 다음 수십 프레임(e.g. 이후 50프레임) 동안 어떻게 움직여야 하는지 50개의 액션(궤적이라고 부름)을 예측한다.
트랜스포머 특성상 생성된 궤적은 잘못된 경우가 당연히 생긴다.
따라서 50개를 모두 실행한 뒤에 다시 다음 궤적을 만드는 것이 아니라, 50개 중 첫 10개 정도의 액션을 로봇이 실제로 실행하고, 실행동안 다음 궤적을 바로 예측한다.
그리고 기존 예측한 궤적과 새로운 궤적을 적절히 연결하는 식으로 궤적을 보정해나가서 최대한 자연스러운 동작을 만들어 준다.
ROS2
원래 로봇을 제어하려면 ROS2 를 알아야 한다. 하지만 현재 당장 제어해야하는 로봇이 있는게 아니라면 ROS2 를 공부할 필요는 없다. (맥북에서 ROS 돌리는게 어렵기도 하고)
먼저 Isaac Sim 같은 시뮬레이션 환경에서 로봇에 대해서 충분히 익숙해지고 나서, 실물 로봇을 제어해야할 일이 생기면 천천히 공부하는 것이 좋다.
공부순서
피지컬 AI 공부하려면 원래는 로봇 팔과 GPU 머신이 있어야 한다고 생각하기 쉽다. 하지만 실제로는 그렇지 않다.
목표가 뭔지부터 설정하고 공부를 시작하는 것이 불필요한 비용을 줄이는 좋은 방법이다. 꼭 실물 로봇팔이 있어야 하는게 아니라면 시뮬레이션 환경에서 로봇을 제어하는 방식으로 시작하는 것을 추천한다.
비용
먼저 비용을 대략 살펴보자.
로봇팔에 대해서는 LeRobot 을 구매하는 것이 일반적인데, LeRobot 의 100 달러 이야기는 어떻게 책정된건지 모르겠지만 실제로는 60만원 정도 든다.
물론 다른 로봇들에 비하면 실제로 싸고 학습과 테스트 할 수 있는 환경도 잘 갖춰져 있지만, 60만원이면 개인이 덜컥 살 수 있는 정도로 싸지는 않다.
학습과 테스트를 위한 GPU 머신같은 경우에도 RTX 4090 정도는 써야하는데 해당 머신을 가지고 있는게 아니면 이걸 위해서 사기는 약간 부담스럽다.
양팔 로봇을 제어하는 경우에는 LeRobot 팔 2개와 프레임, 뎁스 카메라가(리얼센스 등) 추가로 필요하고, 이때는 보통 2개의 리더암으로 제어하는 방식이 아니라 애플 비전프로나 퀘스트 등의 헤드셋 VR 을 사용해서 제어해야 제대로 된 데이터를 수집할 수 있다.
이렇게 양팔 로봇을 해보려는 경우 총 1000만원까지도 들어간다. 따라서 개인적으로는 단일 로봇팔이나 로봇팔 + 이동 (LeKiwi 등) 이 취미 또는 흥미를 위한 최대치라고 생각하지만, 몇년 뒤에는 휴머노이드 로봇도 취미로 만들 수 있을 것이라고 생각한다.
시뮬레이션 먼저하기
여튼 나처럼 취미로 피지컬 AI 를 해보고 싶은 경우에는 실물 로봇을 구매하지 않고, 시뮬레이션 환경에서 로봇을 제어하는 방식으로 시작하는 것을 추천한다.
나는 맥북밖에 없기 때문에 EC2 g6.8xlarge 정도의 인스턴스로 Isaac Lab (Sim) 을 설치하고, 로봇에 대한 제어는 키보드 또는 플스/엑스박스 패드를 사용하는 방식으로 시작했다. (gpu 성능보다 cpu 성능이 많이 필요해서 4xlarge 도 돌아는 가지만 8xlarge 로 했다.)
이후 Isaac Sim 튜토리얼을 하고, Isaac Lab 튜토리얼을 하면 대부분의 내용을 배울 수 있다. LeRobot 도 공식 레포에서 USD 파일을 제공하고 있기 때문에 로봇을 쉽게 시뮬레이션에 임포팅할 수 있다.
이후 인스턴스에 GR00T 을 설치하여 이미 학습된 모델을 한번 돌려본 뒤에, 간단한 매니퓰레이션 작업을 학습시켜서 돌려보면 피지컬 AI 기본은 배운 것이라고 보면 될 것 같다.
개인적으로도, 위의 과정으로 GR00T N1 으로 파인튜닝하고, 맥북에 도커를 띄워서 turtlesim 으로 ROS2 를 공부했고, 아직 실물 로봇이 꼭 필요하지는 않아서 구매는 하지 않았다. (리더암만 사고 싶은데 파는 곳이 없음)
목표를 설정하자
이후에는 본인의 목표에 따라, LeRobot 을 하나 사본다거나, ROS2 를 공부한다거나, GR00T Dreams 로 데이터를 증강해서 학습해본다거나, 퀘스트나 비전프로만 사서 양팔 로봇이나 휴머노이드 로봇을 학습해본다거나 원하는 방향으로 진행하면 된다.
개인적으로는 피지컬 AI 를 하는 것이 AI 를 통해서 로봇을 제어하는 것이므로, 어딘가에서 데모를 해야하는게 아니라면 굳이 실물 로봇을 구매할 필요가 있나 싶다.
마치며
공부를 하다보면 결국 로보틱스는 데이터 싸움이라는 생각이 든다.
최근 춤추는 로봇이나 다양한 로봇들을 중국에서 데모하는데, 해당 로봇들은 대부분 IL+RL 방식을 사용하는 것으로 보인다.
로봇이 아주 작은 개별작업을 잘하는 것을 보여주고, 원하는 작업에 대해서 직접 학습시켜준다는 방식이다. 결과적으로 이 방식은 한계가 있어서 폐기되지 않을까 생각되지만, 데이터 수집 측면에서는 나쁘지 않은 방향인 것 같다.
테슬라가 자율주행 차량 데이터를 확보한 것과 마찬가지로, 최대한 많은, 다양한 데이터를 확보하는 것이 중요하기 때문에 사용자에게 빨리 제품을 떠넘기고 현장 데이터를 확보하는 전략이 더 좋아보이기 때문이다. (아이러니하게도 테슬라는 로봇팜을 만들어서 데이터를 쌓고 있고, 중국은 사용자에게 로봇을 떠넘기는 방식으로 데이터를 확보하고 있다.)
그 와중에 nvidia 와 구글은 생성형 모델로 데이터를 합성하고, 아예 없는 데이터를 생성하는 방식으로 데이터 확보를 하려고 하고 있다.
중국과 미국의 데이터 싸움이 이제 막 시작되고 있는 가운데, 애매한 잡부 개발자로서 뭘 해야할지 고민이 점점 깊어진다.