쉽게 설명한 LSH-Minhash 알고리즘
TL;DR
LSH(Locality sensitive hash) 는 Jaccard Similarity 가 높은 원소들을 같은 버킷에 넣는 해쉬 알고리즘이다.
시작하며
이전 글1에서 이어지는 내용으로 LSH 가 대체 어떻게 동작하는거지? 하는 의문을 해소하기 위한 글이다.
거의 완벽하게 설명한 글2이 있기 때문에 전체 내용을 다시 적지 않을 것이다.
여기서는 내 기준에 여러번 읽어도 이해가 잘 안됐던 내용들만 적어 본다.
가장 직관적인 구현체라고 생각되는 Datasketch3 를 기준으로 구현한 소스 코드를 간략히 설명해보겠다.
설명
LSH: Find documents with Jaccard similarity of at least t
Band partition
우리는 Minhash 를 이용하여 각 문서를 컬럼으로 하는 signature matrix 를 얻을 수 있었다.
그럼 이 signature matrix 의 한 컬럼(문서의 signature) 가지고 어떻게 하면 비슷한 다른 컬럼을 찾을 수 있을까?
LSH(locality sensitive hashing) 알고리즘은 밴드 파티셔닝이라는 방법을 써서 이 문제를 해결한다.
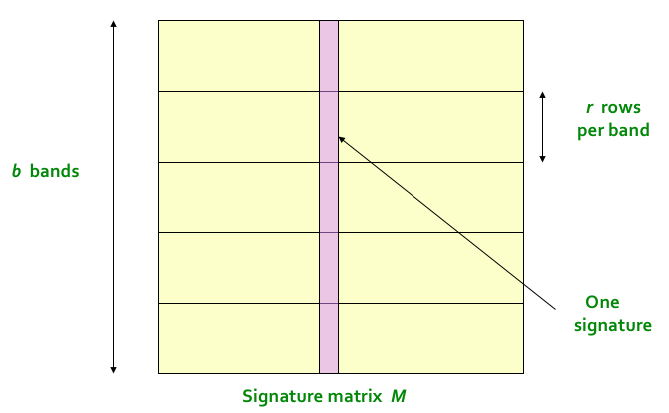
밴드 파티셔닝 알고리즘은 다음과 같다.
- 하나의 컬럼를 b 개의 밴드로 나눈다. 그리고 각 밴드는 r 개의 행으로 구성되어 있다. 그림을 보면 알 수 있듯이
b * r == number of rows in a signature가 된다. 예를 들면 한 문서의 signature 의 길이가 100 이고 (즉, 위 그림에서 분홍색 라인의 길이가 100 이고) 밴드의 개수가 20 이라면 각 밴드별로 5 개의 열을 할당받게 된다. - 각 밴드는 k 개의 버킷을 가지고 있고, 밴드별로 할당된 signature 의 열을 k 개의 버킷에 해싱한다.
- 2에서 두개의 컬럼을 해싱 할 때 하나의 밴드라도 동일한 버킷에 들어간다면 두 컬럼은 비슷하다고 본다.(candidate)
아래 그림은 2, 3번 단계를 설명하고 있다.

그럼 b 와 r 을 어떻게 정하면 될까?
Characteristics of b & r
b 와 r 을 정하기전에 먼저 해당 값들의 특성을 살펴보자.
확률론에 대해서 어느정도 알고 있다면 본문1의 설명으로 충분하므로, 여기서는 가능하면 수학적인 내용을 배제하고 써본다.(확률기초 내용은 Head first Statistics 를 강력 추천한다.)
본문에서는 b 의 의미를 아래와 같이 설명하고 있다.
b 가 커지면 similarity threshold 가 낮다(higher false positives) 는 것을 의미하고
b 가 작아지면 similarity threshold 가 높다(higher false negatives) 는 것을 의미한다.
위의 1번에서 설명했듯이, b * r == number of rows in a signature 이다. 따라서 signature 크기는 정해져있기 때문에, b 가 커지면 r 은 작아지게 된다.
알고리즘에서는 하나의 band 에 들어있는 모든 row 를 해시한 값이 일치하면 비슷한 문서라고 판단한다고 했다.
그러면 직관적으로 각 row 가 비슷할 가능성이 동일하다고 하면, [2, 1] 처럼 row 가 2개가 포함된 band 보다 [1] 처럼 row 가 1개만 포함된 band 가 비슷할 가능성이 높다고 볼 수 있을 것이기 때문에 row 가 낮을수록 문서를 비슷하다고 판단할 확률이 높아진다고 볼 수 있다.
또, false positive 는 비슷하지 않은데 비슷하다고 판단하는 오류이고(즉, 모델이 내놓은 결과인 positive 가 false 라는 의미), false negative 는 비슷한데 비슷하지 않다고 판단하는 오류이다(즉, negative 라고 모델이 내놓은 결과인 negative 가 false 라는 의미).
직관적으로 어떤 물건 두개가 비슷하지 않은데 비슷하다고 판단하려면 더 적은 근거를 가지고 판단해야 한다. 즉, 코끼리를 여러 장님들이 더듬어 표현할 때 모든 사람이 코를 만지고 표현하는 것이 코와 귀와 다리와 꼬리를 모두 만지고 표현하는 것보다 더 일치할 가능성이 높다. (여담이지만 xgboost, 랜덤포레스트 같은 앙상블 방식들은 이런 이유로 성능이 잘 나오는 편이다.)
따라서 b 와 r 을 어떻게 정하느냐에 따라 위에 설명한대로 false positive 와 false negative 값도 변화하게 된다.
Choose b & r and Similarity Threshold t
알고리즘에서는 하나의 band 라도 해시값이 일치하면 비슷한 문서라고 판단한다고 했다.
그럼 최소 하나 이상의 밴드가 일치할 확률 을 가장 높일 수 있는 b 와 r 을 구하면 되지 않을까?

위의 우측에 있는 식이 바로 그 식이다. 여기서 t 는 Similarity Threshold 라고 부르는데, Jaccard Simialrity 와 동일한 개념이다. 이 값은 두개의 서로 다른 컬럼이 있을때 하나의 row 가 동일할 확률이며 이를 이용하여 최소 하나 이상의 밴드가 일치할 확률 을 위의 식을 이용하여 계산할 수 있다.

위 그림은 signature 길이가 200 이고 t 가 0.17 일때, 즉 두 문서의 Jaccard similarity 가 0.17 이상일때 최소 하나 이상의 밴드가 일치할 확률 을 나타내는 그래프이다.
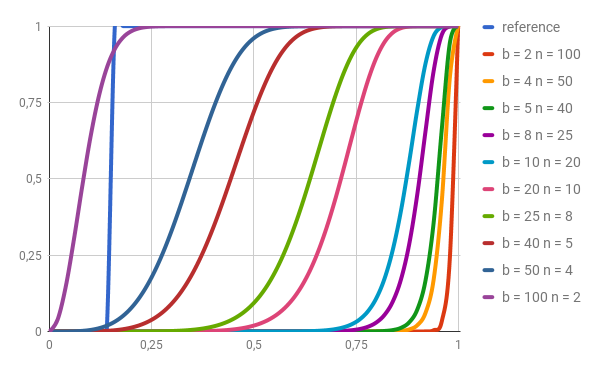
b 와 r (그래프 에서는 n) 을 조정하면서 확인해보면 reference 인 원래 그래프와 가장 비슷하게 나타나는 그래프는 b = 100, r = 2 일 때이다. 따라서 해당 값으로 b 와 r 을 설정하고 LSH 알고리즘을 계산하면 두 문서간의 Jaccard Simialrity 가 0.17 이상이면 비슷한 문서로 분류되는 해시함수를 얻을 수 있다.
구현
컨셉
TODO: 디테일한 설명 추가
코드 설명
코드는 여기4
TODO: 디테일한 설명 추가
마치며
LSH 는 데이터를 어떻게 전처리하냐에 따라, 비슷한 사용자, 비슷한 아이템5, 비슷한 이미지 찾기6 등 여러 곳에서 사용할 수 있는 유용한 알고리즘이다.