M1 맥북에서 ComfyUI 로 SDXL-Turbo 로 이미지 생성하기
2024년 01월 22일 작성TL;DR
M1 맥북프로 14인치 16G 모델에서 512x512 이미지 1장에 2~3초 정도 걸린다.
시작하며
최근에 스테이블 디퓨전을 다시 해야할 일이 있어서 팔로우-업을 하고 있는데 SDXL-Turbo1 가 꽤 재미있어 보였다. 예전에 segmind 의 ssd-1b1 모델을 보면서 엄청 감탄한 적이 있었는데, stability.ai 에서도 비슷한 작업을 한 결과가 SDXL-Turbo 이다.
ADD (Adversarial Diffusion Distillation)2 라는 방법을 통해 SDXL 에서 knowledge distillation 하여 3.1B 크기 모델을 만들었다.
이 모델이 맥북에서 잘 돌아간다고 해서 돌려보니 꽤 괜찮았다.
인스트럭션 같은 글은 잘 안올리는 편이지만 모델자체가 꽤 유용해서 어떻게 돌리는지 간단히 기록겸 정리해둔다.
아래 실험 환경은 M1 맥북프로 14인치 16G 기본모델이다.
ComfyUI 클로닝
SD 모델 WebUI 툴의 de facto 는 Automatic1111 이지만, 요새 로컬에서 좀 더 빠르게 돌리고 싶을땐 ComfyUI3 를 많이 쓰는 것 같다.
모듈러 방식으로 UI 가 구성되어 있어서 모듈을 바꿔가면서 실험을 해야할 경우 Automatic1111 보다 더 나은것 같다.
ComfyUI 는 따로 설치 같은 개념이 없고 그냥 git 으로 클로닝하면 된다. 파이썬 서버이므로 pip 로 requirement.txt 에 있는 의존성을 설치해준다.
해당 레포의 README 에 Apple Mac Silicon 섹션을 참고하면 된다.
$ pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
$ git clone https://github.com/comfyanonymous/ComfyUI
$ cd ComfyUI
$ pip3 install -r requirements.txt
SDXL-Turbo 모델 다운로드
SDXL-Turbo 모델은 stability.ai 에서 다운로드 받을 수 있다.
인터넷에 돌아다니는 모델 받는 방법은 크게 아래 3가지 인 것 같다.
- huggingface-cli 로 받는 방법
- wget 으로 받는 방법
- git-lfs (large file storage)4 로 받는 방법
여기서는 3번째 방법으로 받았다. git-lfs 는 homebrew 로 설치하면 편하다. (홈페이지에 다양한 설치방법이 있음)
git 의 특성상 clone 을 하면 레포지토리의 전체 리비전에 해당 하는 파일을 모두 다 받아오기 때문에 ML 모델을 받으면 엄청 거대한 양을 받아야 한다. 이 때 git-lfs 를 사용하면 지정된 리비전에(예, HEAD) 포함되지 않은 파일은 받아오지 않고, 포인터로 처리해서 필요할 때만 받아오기 때문에 효율적이다.
$ brew install git-lfs
$ git lfs install # only once per user account
이후 git clone 으로 huggingface 모델 레포지토리에서 모델을 ComfyUI/models/checkpoints 폴더에 받는다.
$ cd models/checkpoints
$ git clone https://huggingface.co/stabilityai/sdxl-turbo
fp32, fp16 모델 두개가 다 등록되어 있기 때문에, 합쳐서 대략 80기가 정도 받는다.
ComfyUI 실행
$ cd ../.. # ComfyUI 루트 폴더로 이동
$ python main.py --force-fp16
이후 브라우저에서 8188 포트로 접속하면 아래와 같은 화면을 볼 수 있다.
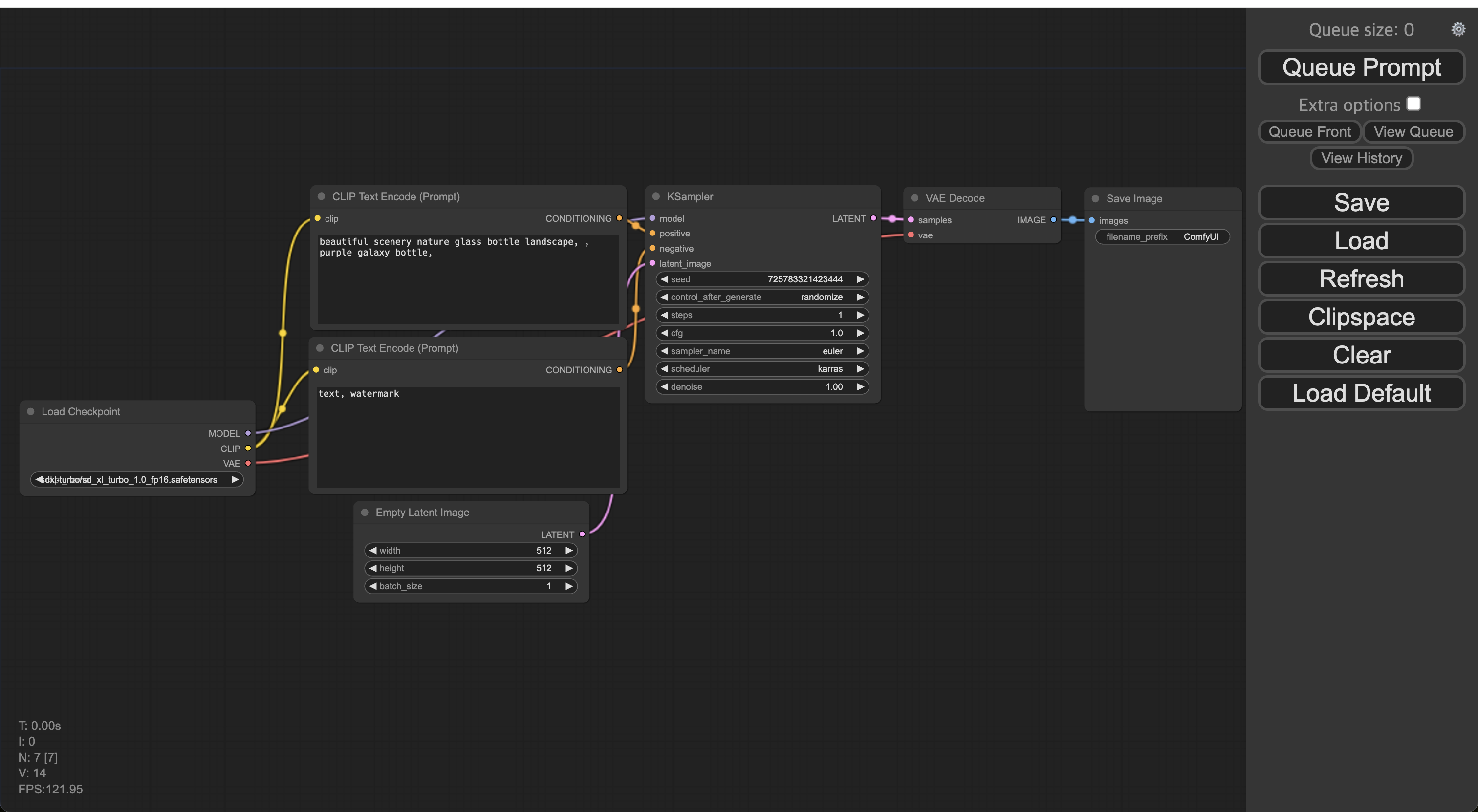
이미지 생성
위의 워크플로우는 기본 템플릿이므로 이미지를 여러장 출력한다거나 하는 등 원하는대로 수정해서 쓰면 된다. 여기서는 워크플로우는 그대로 써본다.
왼쪽부터 오른쪽으로 실행되는 흐름이므로 하나씩 설정해주고 우측 상단에 있는 Queue Prompt 를 클릭하면 이미지가 생성된다.
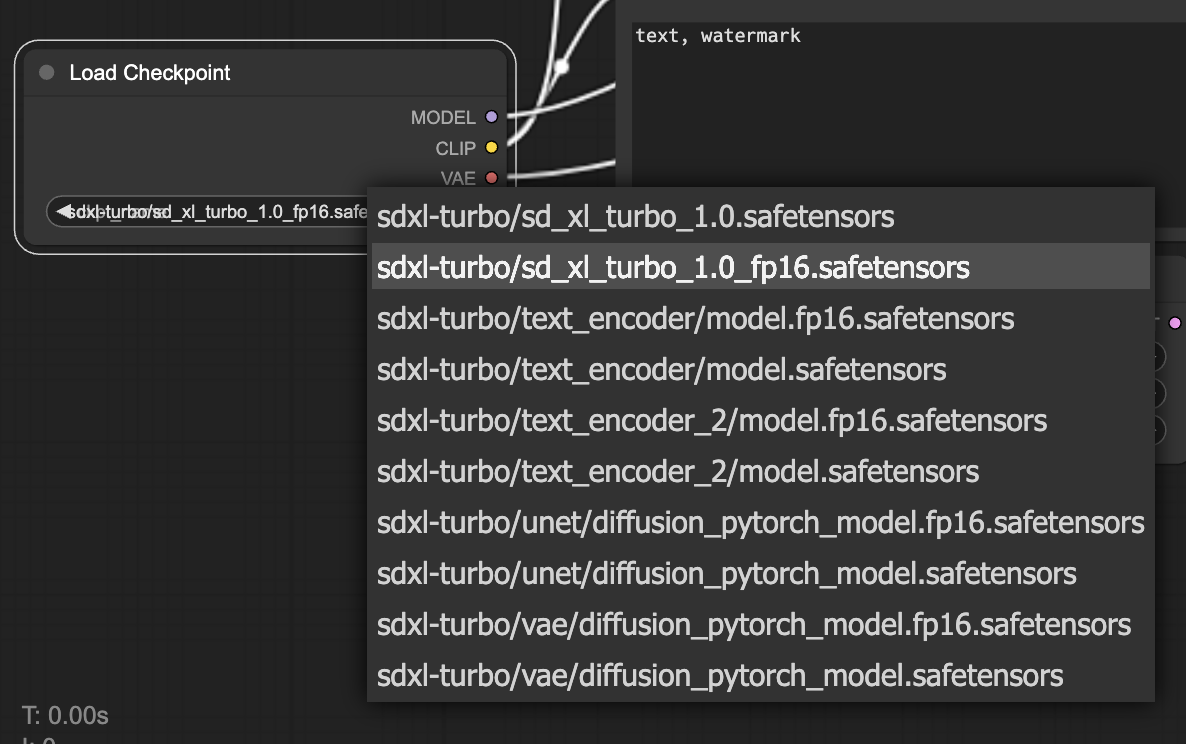
먼저 체크포인트를 fp16 모델로 선택한다.
다른건 딱히 설명할 게 없고 중간에 있는 KSampler 에서 steps, cfg, sampler_name, scheduler 만 아래 그림과 같이 설정해준다.
값은 각각, 1, 1.0, ‘euler’, ‘karras’ 이다.
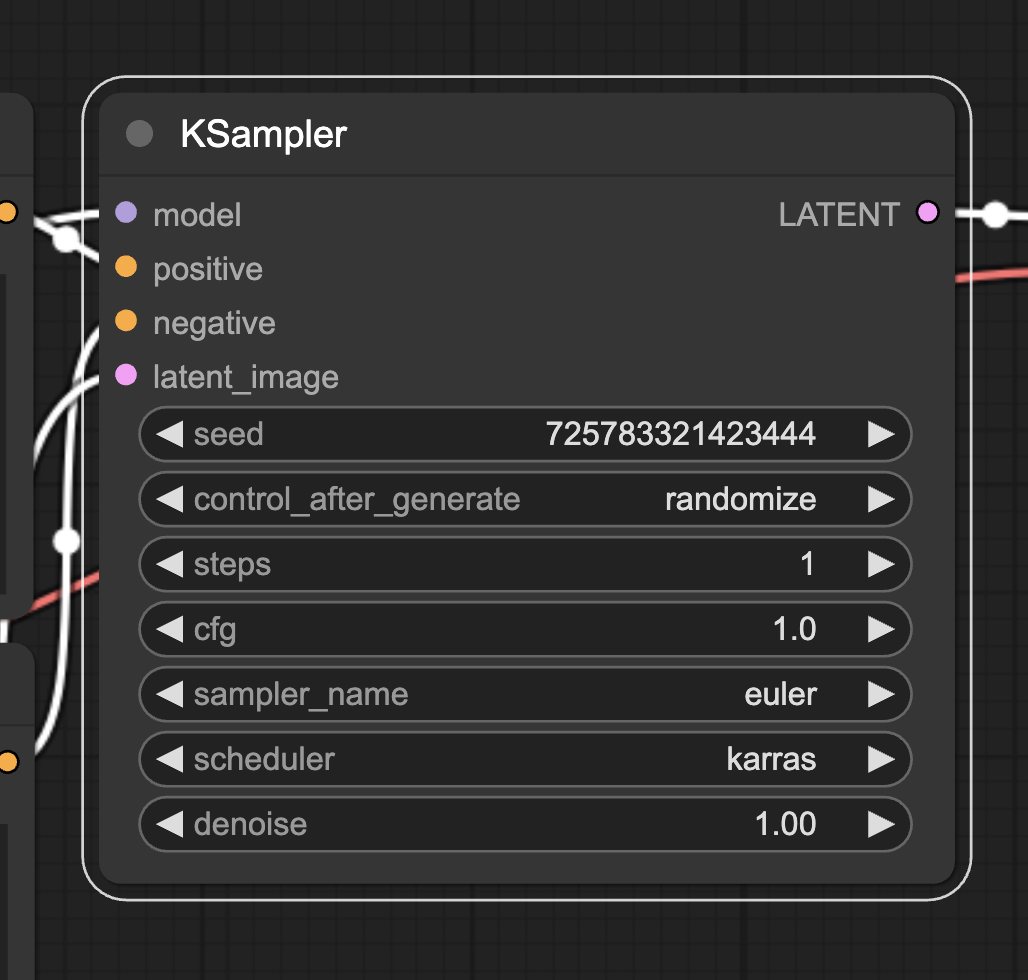
각 값이 무슨 의미인지는 예전 글5의 샘플러부분에 대충 적어두었다.
SDXL-Turbo 모델은 1~4 스텝이면 충분하다. 논문상에 따르면 사람이 선호도 측정했을때 50스텝 SDXL 와 4 스텝 SDXL-Turbo 의 차이가 거의 없다고 한다. 그리고 1 스텝만으로도 충분히 납득할만한 이미지가 나온다고 한다.
이렇게 해두고 Queue Prompt 를 클릭하면 이미지가 생성된다. 첫 이미지 생성은 모델 로드 시간이 좀 걸리지만, 두번째 이미지부터는 2~3초 정도 걸린다.

마치며
이미지 생성 속도는 512x512 이미지 1장에 2~3초 정도 걸린다. AWS g5.8xlarge 나 inf2.12xlarge 에 해당 모델을 올려서 생성해보면 768x768 이미지 1장 생성시 0.25초 정도 걸린다.
참고로 AWS Bedrock 에는 SDXL 1.0 모델만 지원되는데, 50 스텝에 대략 2초정도 걸리고, 이는 inf2.12xlarge 에서의 속도와 비슷하다.